
前言
正则表达式 (Regular Expression) 是一种强大的文本模式描述语言,可以通过简洁的符号组合描述复杂的字符串匹配规则。被广泛应用于数据验证、文本提取、日志分析等领域,在我们日常工作中发挥着重要的作用。
软件行业从业,是否掌握正则表达式的使用,往往是区分菜鸟和老手的重要标识。 本文我们结合一些具体案例,详细梳理下正则表达式的应用,早日告别新手村!
正则表达式核心语法
学习正则表达式, 这里推荐一个非常直观的线上验证平台, https://regex101.com , 对于我们练习和掌握正则语法非常有帮助。
普通字符和特殊字符
正则表达式作为一个匹配规则。当然首先可以匹配各种普通字符。主要指各种中英文单词、字母、数字。此外正则表达式还会预留很多特殊字符,如 * ? + . () [] $ ^ \ | 等,代表一些特别的匹配规则,而如果这些特殊字符我们需要看作普通字符进行匹配时,则需要使用 \ 符号进行转义,因此 \ 也称转义符。比如 \? 就会匹配目标文本中的 ? 字符, \\ 则会匹配目标文本中的 \ 字符
量词符(quantifiers)
量词符是用于控制匹配次数的符号:
*零次或多次(如a*可匹配 “”, “a”, “aa”)+一次或多次(a+必须至少有一个a)?零次或一次(a?可匹配 "" 或 a){n}精确匹配n次({4}匹配4次){m,n}匹配m到n次(含边界){m,}匹配m到多次{,n}匹配零次到n次
另外,在正则表达式中,还有两种匹配模式
- 贪婪模式:这是默认模式,也就会在目标文本中,尽可能最长地去匹配符合规则的字符
- 惰性模式:而如果在量词后加
?则标记以惰性模式进行匹配,也就是尽可能少地去匹配符合规则的字符
举例来说:
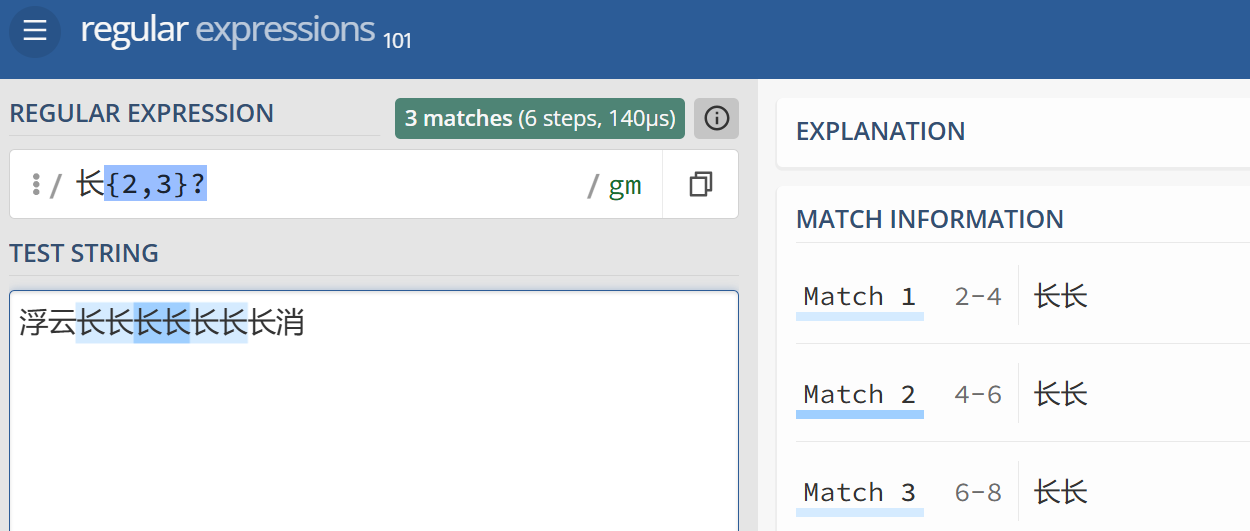
浮云长长长长长长长消
这个上联中有 7 个 长 字,正则表达式 长{2,3} 默认按贪婪模式匹配,会匹配到 2 次 长长长, 而加上 长{2,3}? 则会按尽量少的字符匹配,匹配到 3 次 长长
元字符(Metacharacters)
除量词符外,还有一类元字符,被预留构成正则表达式的基础特殊符号:
\d匹配数字(等价于[0-9])\D匹配非数字\w匹配单词,包括字母、数字和下划线(等价于[A-Za-z0-9_])\W匹配非单词\s匹配空白符(空格/制表符/换行符)\S匹配非空白.匹配任意单个字符(默认不匹配换行符)|表示逻辑"或"
位置限定符(Position Anchors)
用于精准定位匹配位置:
\b匹配单词边界(如\bcat\b匹配完整单词)\B匹配非单词边界^匹配目标文本开头,多行模式下也匹配行首$匹配目标文本结尾,多行模式下也匹配行尾
举例来说:
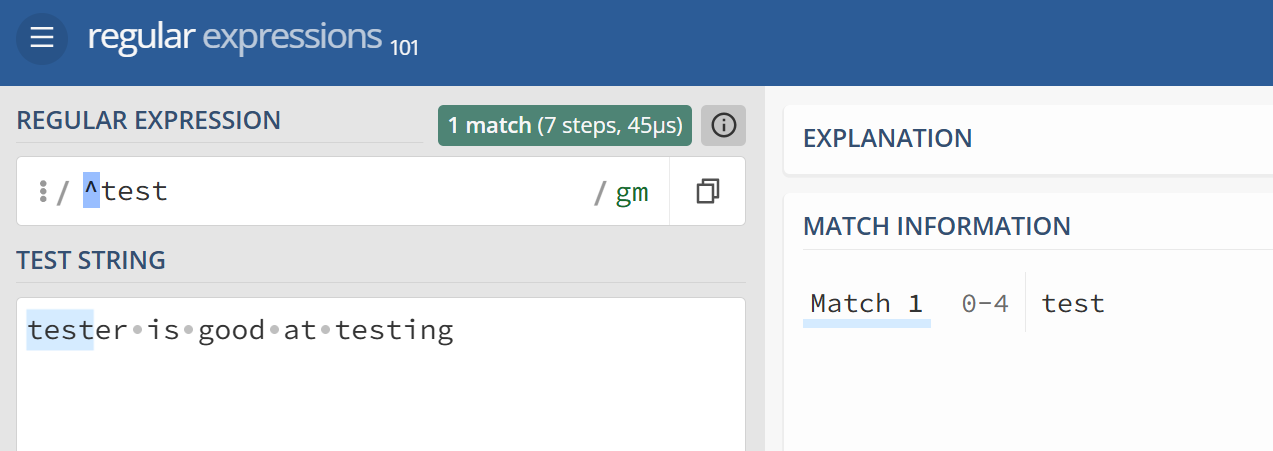
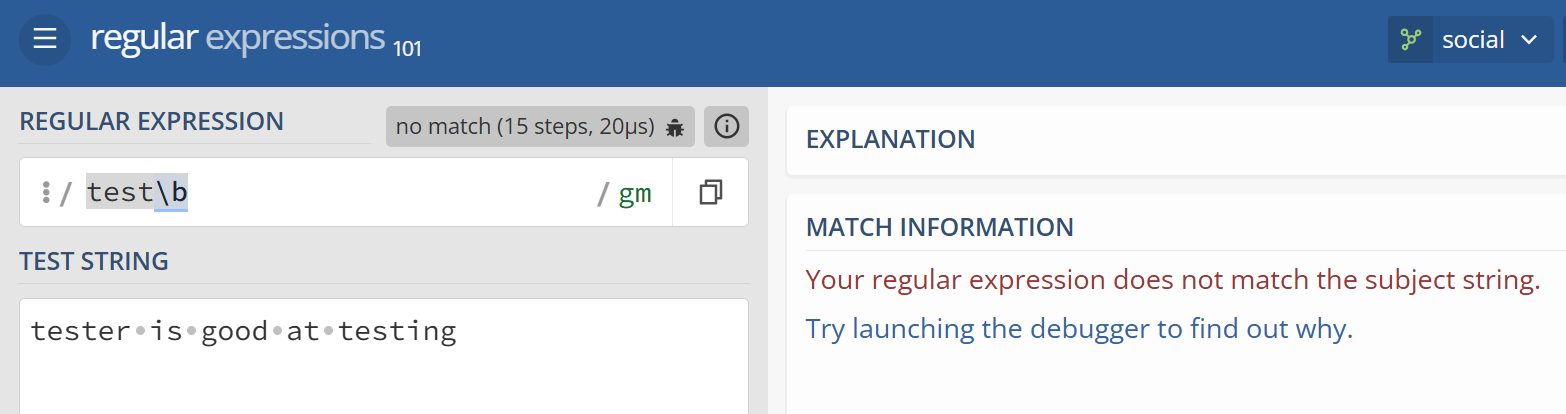
在tester is good at testing 中,用 ^test 就只会匹配到行首的 test, 但testing 中的test 就不会匹配到, 而如果 test\b,同样匹配不到任何结果,因为这段文本中 test都不是单独的单词,test 后不存在单词边界
字符类(Character Classes)
字符类用于批量匹配特定字符集合:
[abc]匹配a/b/c中的任意字符[^abc]匹配不在集合中的字符- 范围表示法:
[a-z](小写字母)、[A-Z](大写字母)、[0-9](数字)
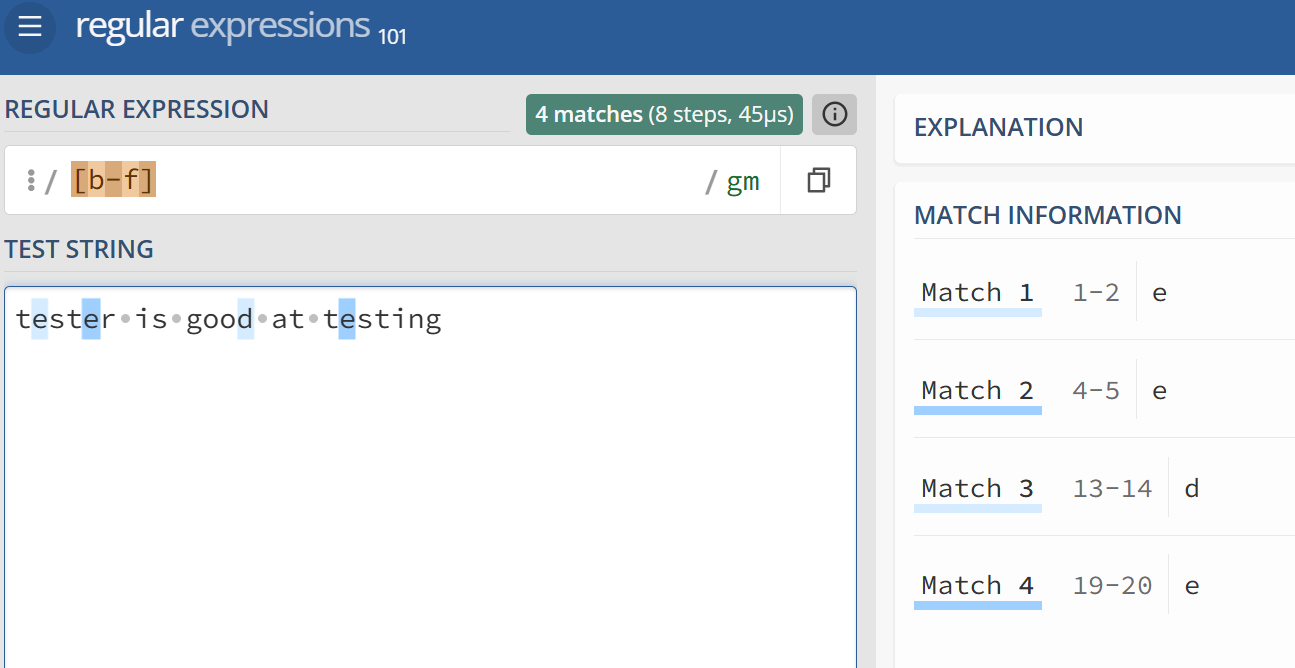
下例中 [b-f], 就只匹配了目标字串中的 d,e
分组(Groups)
分组是正则表达式中重要的技巧,用于对匹配规则进行分组,便于在后续的文本处理中提取匹配到的内容。 分组通过在表达式中将模式用 () 框定来表示。
比如指定一个字串
|
|
分组及其引用
分组默认从 1 开始计数,也就是多个分组时,可以按顺序以 \1 \2 来反向引用分组
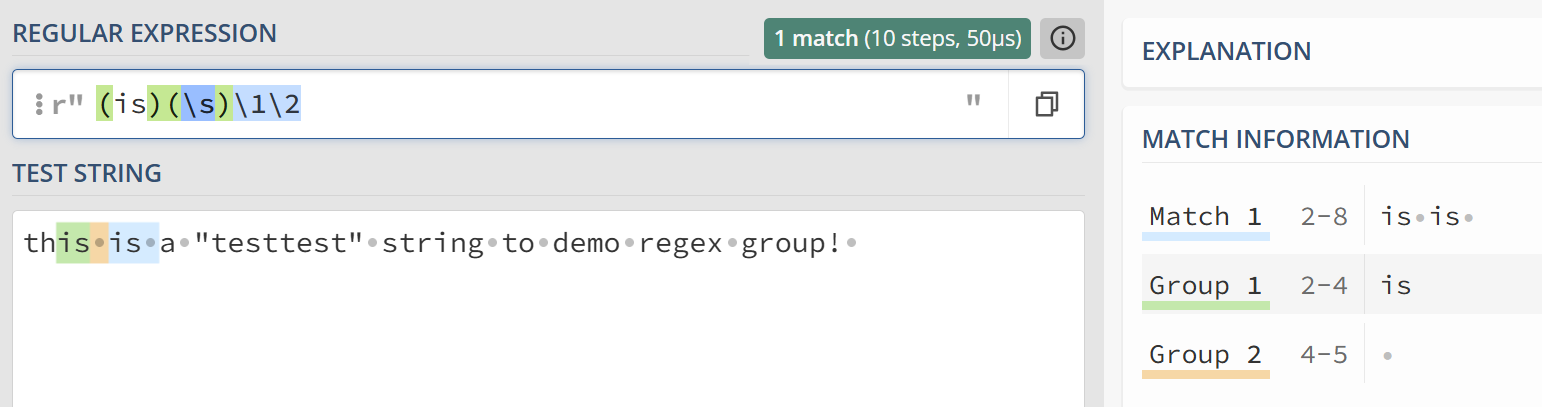
这个例子,我们 通过 (is)(\s)\1\2 指定了两个分组,组1 匹配 “is”, 组2匹配空白字符(这里是空格) ,然后用\1\2 分别引用这两个组,最终其实就匹配了 "is"+空格 连续出现了两次的情况
指定分组不进行引用
如果我们进行分组时,某个分组我们并不想在后续引用,那么可以使用 (?:pattern) 来进行标记,指定当前分组在后续不会进行引用。 这时分组默认的提取序号中,就会忽略这一组不进行编号
。
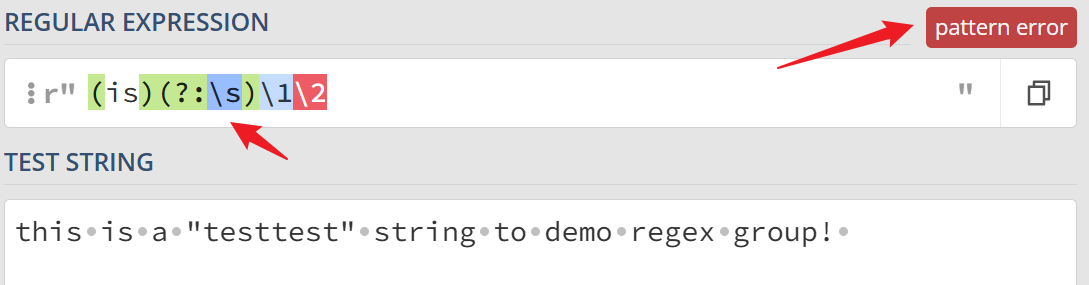
上例中,如果我们指定其中第二个分组不进行引用
|
|
这时其实上例中的正则表达式就出现语法错误,无法完成匹配,因为这时第二个分组被忽略,而 \2 进行引用,这时就会因为不存在出现模式错误
对分组进行注释
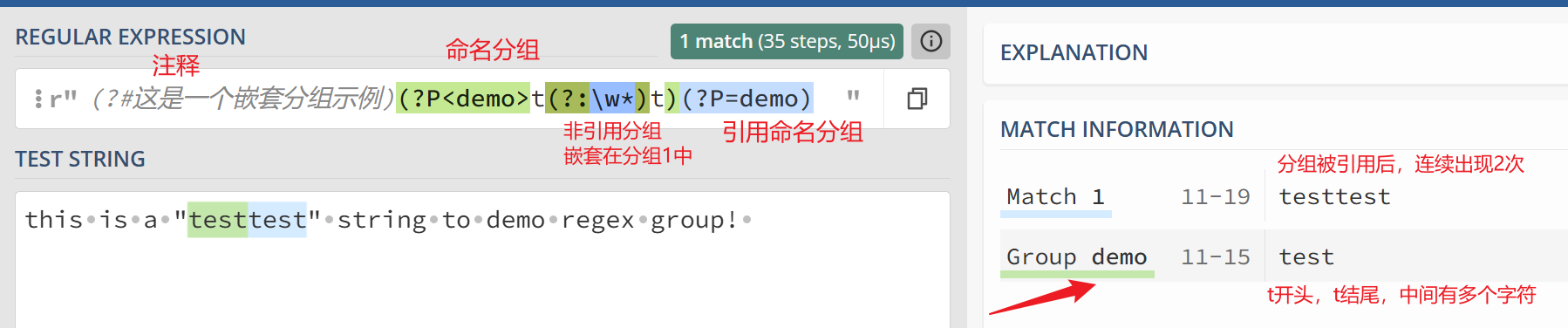
一些复杂的正则表达式,我们还可以在分组添加注释,起到对正则表达式进行说明的作用 (?#comment)(other group)
分组命名
除了默认用数字序号来引用分组,也可以通过给分组进行命名的方式: (?P<name>pattern) 进行命名。
然后用(?P=<name>)进行引用
综合上面的说明,使用如下正则说明
|
|
断言(Assertions)
断言主要用于判断,用来匹配符合模式的字符所在位置。因为它主要用判断位置,不会消费字符,所以一般也叫 零宽断言
断言可分为4类,还是用上例中的文本举例
|
|
正向肯定断言
判断匹配位置之后的字符符合模式, 通过(?=pattern) 来进行断言
示例:

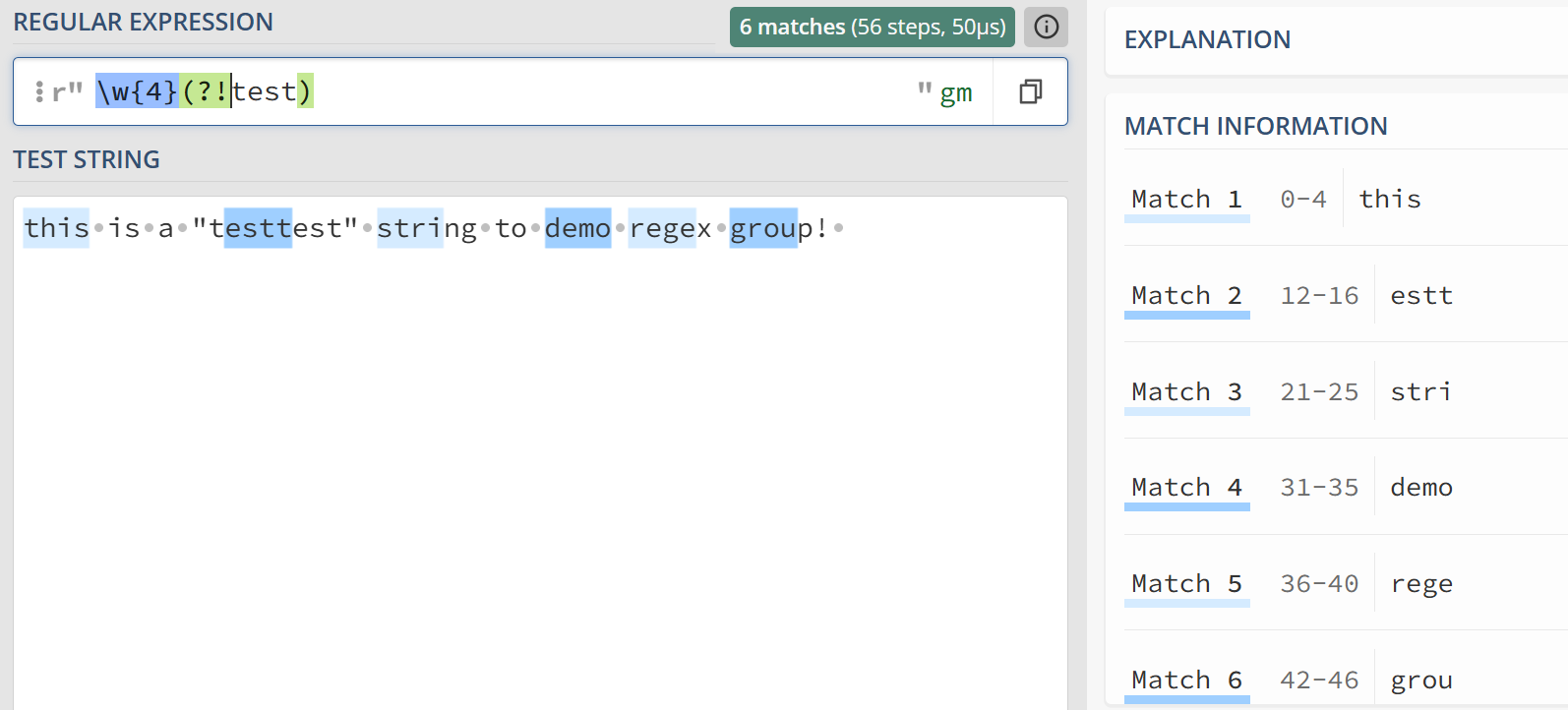
正向否定断言
判断匹配位置之后的字符不符合给定模式, 通过(?!pattern) 来进行断言
示例:
反向肯定断言和反向否定断言
和正向相对,反向断言匹配的是预期位置之前的字符是否符合模式,也有肯定和否定之分。在 ?后再添加一个<表示反向, 即(?<=pattern) 和 (?<!pattern)
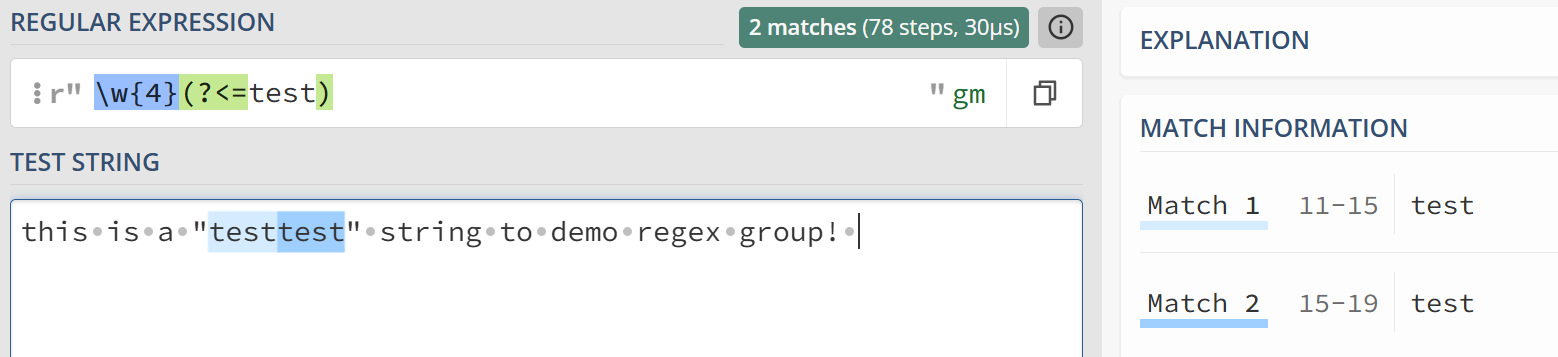
匹配模式
除了上述正则表达式的主要匹配规则外,正则表达式还有一些匹配模式。是用 \ 加上一些特殊的字母代表不同的模式
\g表示全局匹配,也就是会在给定的文本中匹配所有符合条件的字串,如果不指定,则仅匹配出现的第一个符合模式的字串\m多行模式,主要是指定^ $是否匹配行首行尾\i匹配时忽略大小写\x匹配时是否忽略我们模式文本中的空白,在编写比较复杂规则时较为有用\s指定.匹配字符时包含换行符\u匹配unicode字符,如中文\a仅匹配ascii字符
实用案例
针对下面这段文本:
|
|
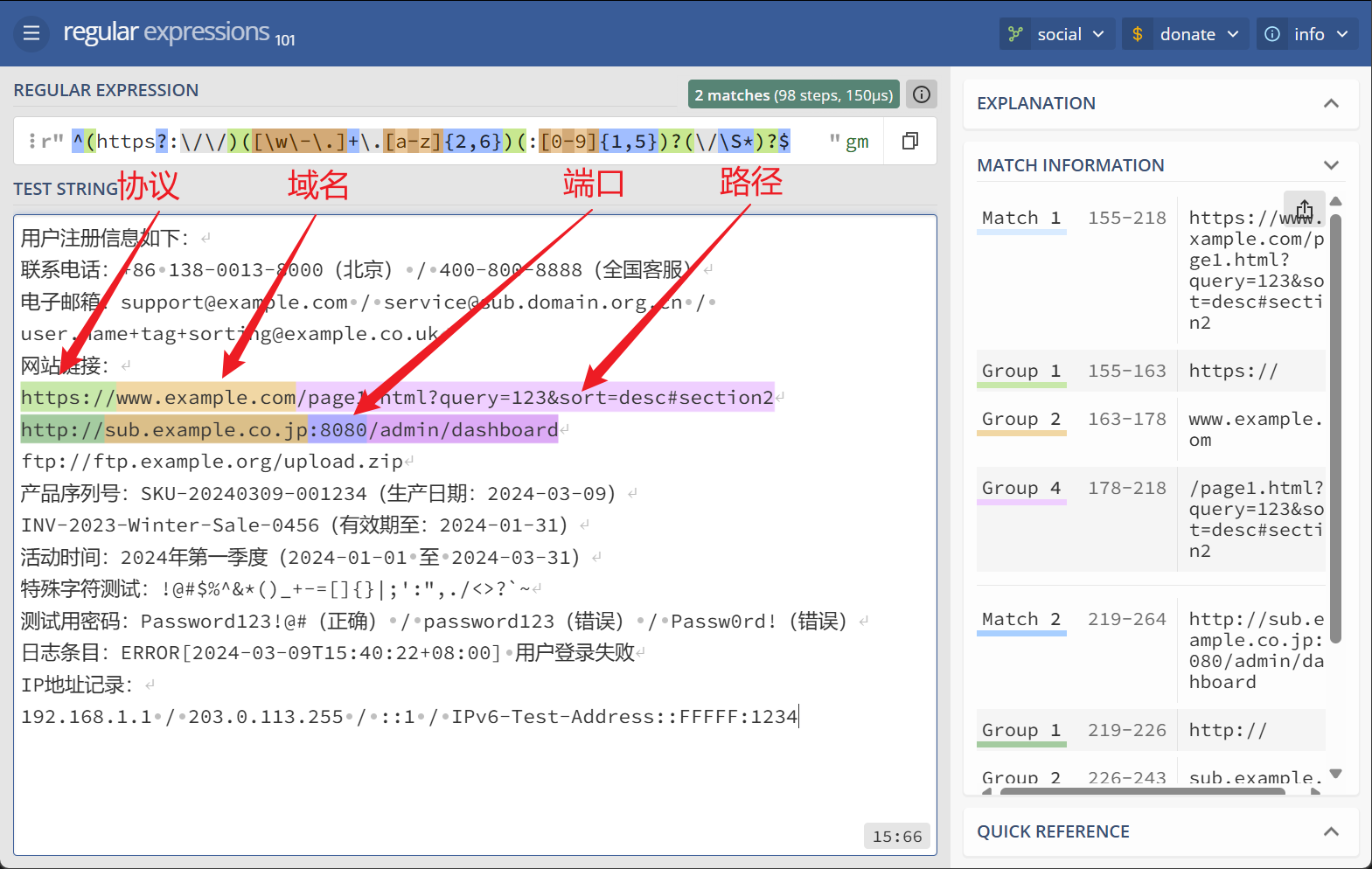
匹配完整URL(含协议、域名、端口、路径)
|
|
匹配结果:
提取电话号码
|
|
说明:首先\b匹配单词边界,用分组提取国家码(2-3位,兼容有+情况),跟-或空格,惰性模式,再匹配3-4个数字和-连续多次出现的情况
匹配结果:
+86 138-0013-8000400-800-8888
验证电子邮箱地址
|
|
匹配结果:
support@example.comservice@sub.domain.org.cnsorting@example.co.uk
捕获产品序列号(包含日期和唯一编码)
|
|
匹配结果:
SKU-20240309-001234INV-2023-Winter-Sale-0456
匹配中文
|
|
解析日志条目中的时间戳
|
|
分组提取结果:
2024-03-09T15:40:22+08:00
提取IP地址
|
|
匹配结果:
- 192.168.1.1
- 203.0.113.255
结语
以上就是针对正则表达式的相关总结和部分案例演示。更多关于测试技能系统提升的学习可关注我的课程,回复 大纲 获取详细目录。