
11-18互联网安息日,cloudflare中断故障回顾

故障影响
在 11月18日,号称“赛博佛祖”的全球基础网络服务提供商 Cloudflare 遭遇自2019年以来最严重的服务中断故障。造成极大范围的影响。
使用cloudflare服务的互联网站点,包括X、chatGPT、Claude等知名站点,以及几乎所有"你懂的"站点,均出现无法访问的现象。
故障导致的中断时间多达6个多小时,有坊间传言是因为cloudflare的工程师因为无法访问因为该故障导致中断的ChatGPT,影响了修复效率。 😂😂😂
 也从另一个侧面,反映了这个服务中断的影响之大!
也从另一个侧面,反映了这个服务中断的影响之大!
问题来龙去脉
回到事情发生的起点,UTC时间 18日 11:05 之前,cloudflare提供服务的各种网站还岁月静好,但从11:20左右,大量网站开始大量出现 “5XX-服务端内部错误”, 可以说是断崖式的服务中断。
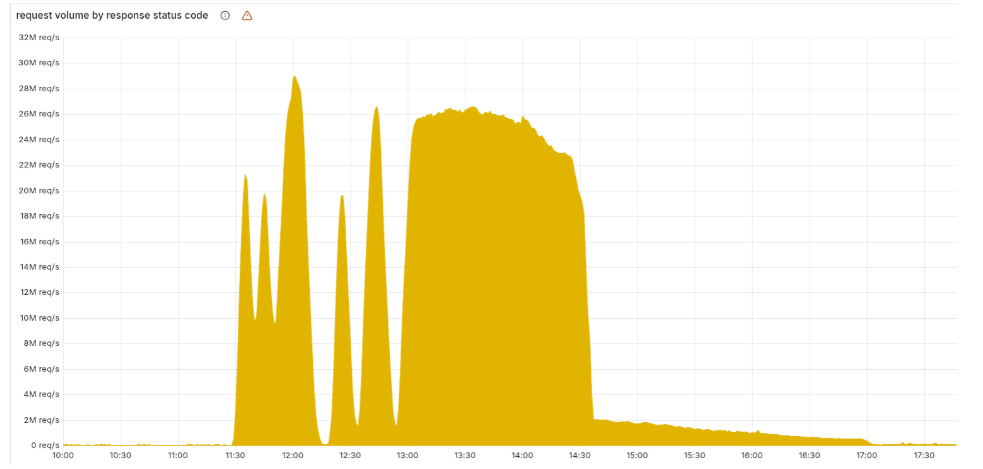
包括 核心CDN、身份校验, 甚至内部监控故障的仪表盘都无法正常使用。
这种反常的故障现象,让CloudFlare的工程师,最开始以为受到了大规模的网络攻击,遭遇了强大的敌人,甚至是里应外合式的攻击。其内部聊天室里,怀疑是另一次 Aisuru DDOS 攻击
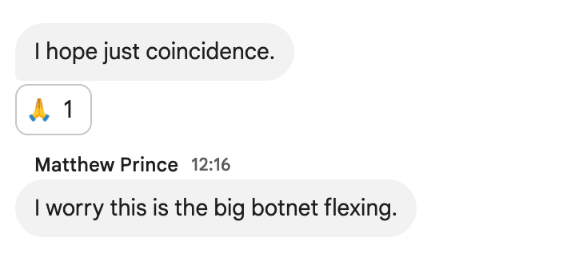
所以在开始其实耗费了很多精力在寻找这个“幽灵攻击”。
但调查到后来发现,真正的原因却让人大跌眼镜。
机器人管理
在大规模应用AI技术的今天,CloudFlare也不例外,它通过一个 机器人管理 模块,基于AI的机器学习模型,来为各种安全和配置策略评分并进而控制网络访问。
在这个模型中,会需要接受一个 feature file 作为输入,正是这个用作 AI 输入的文件,导致了本次史诗级的Bug。
- 首先是一次常规的维护工作,为了提高安全性,调整了数据库权限,希望将公用的“系统账号”,更改为责任更明确的“个人账号”
- 正是这个改动,触发了一个隐藏的问题。也就是生成"feature file"的那段代码。这段代码之前只从默认数据库中查找 feature 清单,但在这次权限变更后,它突然能够访问另一个备用数据库了。而代码中并没有限定读取的数据库源,导致所有的feature,被读取了两次, 结果就是生成的 feature file 成倍地膨胀了。
- cloudflare 的机器人管理模块,为了保证处理效率,对于feature file还有一个限制,就是这个名单不能超过200条
- 而膨胀后的feature file已经超过了这个限制,并因此触发了内存溢出保护机制。
- 程序崩溃,为安全起见,服务连接被全部自动切断
整个问题处理的时间线如下图:
| |
总而言之,根源是一次微小的数据库权限变更!
教训
官方在问题解决后,也第一时间进行了反思,总结了如下四条举措:
强化对 Cloudflare 生成的配置文件的摄取,使其与用户生成的输入文件一样安全
为各个特征启用更多全局终止开关
防止核心转储或其他错误报告占用过多系统资源
审核所有核心代理模块中的故障模式,找出错误原因
而从质量视角,我们可能要反思:
- 为什么这种权限变更,直接在生产环境上应用?有无经过测试?
- 为什么会出现故障单点,并扩散到全局?
- 异常保护为什么会导致程序崩溃?
🥲疑似嫌疑人
下面这个小哥 18号发贴入职cloudflare
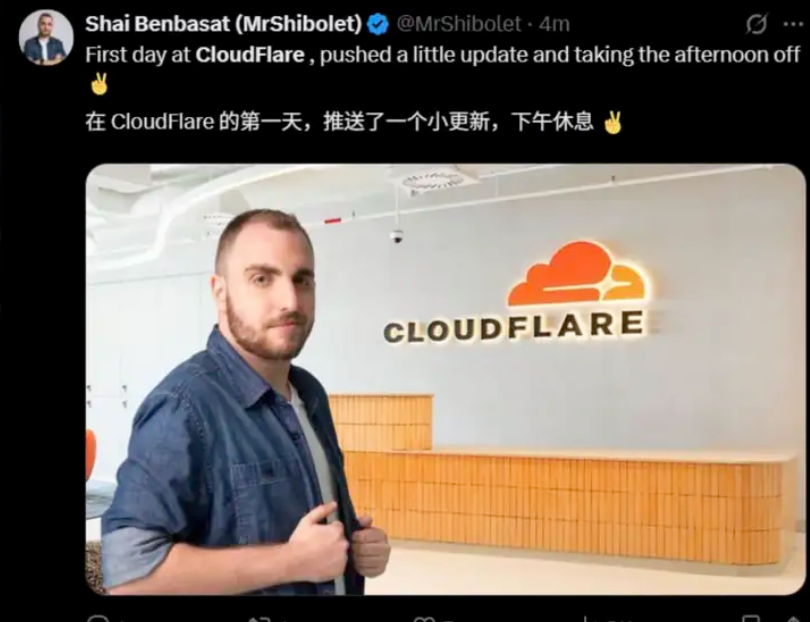
19号更新,开始寻找新工作

巨大的草台班子….. 😂😂😂😂