
引言
开发过Python程序或通过Python编写自动化脚本,都知道日志对于一个程序的重要性。 Python语言也内建了一个日志处理的标准库 logging, 但这个库的使用相对比较复杂。
本文我们介绍一个目前很受欢迎的第三方日志框架 Loguru, 在Github上已有超过22K星标。是一个比 logging更加直观易用的替代方案。开发者可以专注于业务逻辑而不是日志配置的繁琐细节
Loguru的使用
1. 安装和快速开始
最简单的使用方式:
1
2
3
| from loguru import logger
logger.debug("Happy logging with Loguru!")
|
输出:
1
| 2025-08-01 14:00:51.069 | DEBUG | __main__:<module>:3 - Happy logging with Loguru!
|
2. 日志级别
Loguru提供了7个内置日志级别, 并对不同级别设定了不同的默认颜色显示:
| 级别 | 方法 | 数值 | 用途 |
|---|
| TRACE | logger.trace() | 5 | 极其详细的调试信息 |
| DEBUG | logger.debug() | 10 | 开发调试信息 |
| INFO | logger.info() | 20 | 一般信息 |
| SUCCESS | logger.success() | 25 | 成功操作通知 |
| WARNING | logger.warning() | 30 | 警告信息 |
| ERROR | logger.error() | 40 | 错误信息 |
| CRITICAL | logger.critical() | 50 | 严重错误 |
示例代码:
1
2
3
4
5
6
7
8
9
| from loguru import logger
logger.trace("A trace message.")
logger.debug("A debug message.")
logger.info("An info message.")
logger.success("A success message.")
logger.warning("A warning message.")
logger.error("An error message.")
logger.critical("A critical message.")
|
输出:
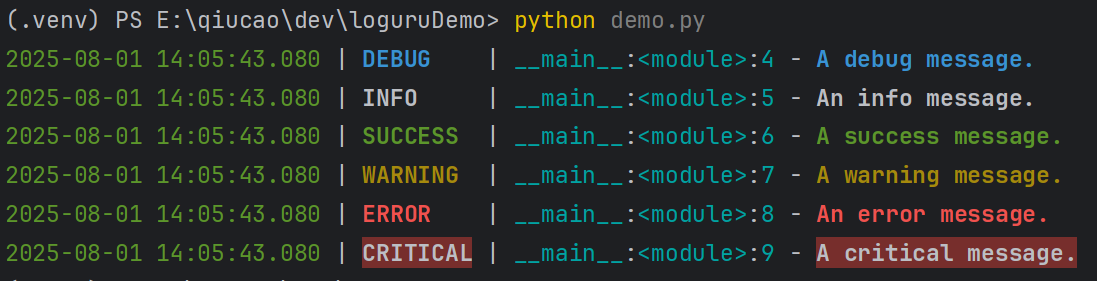
3. 自定义日志级别
loguru 创建自定义的级别也极为方便,比如创建一个 FATAL 级别的日志
1
2
3
4
5
| from loguru import logger
# 创建自定义级别
logger.level("FATAL", no=60, color="", icon="!!!")
logger.log("FATAL", "A fatal error occurred.")
|
进阶用法
1. 日志处理器配置
Loguru使用add()方法添加处理器:
1
2
3
4
5
6
7
8
9
10
| import sys
from loguru import logger
# 移除默认处理器
logger.remove()
# 添加自定义处理器
logger.add(sys.stderr, level="INFO", format="{time:YYYY-MM-DD HH:mm:ss} | {level} | {message}")
logger.log("INFO","配置完成,开始记录日志")
|
2. 文件日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from loguru import logger
# 基本文件日志
logger.add("app.log", rotation="500 MB", retention="10 days", compression="zip")
# 高级文件日志配置
logger.add(
"app_{time:YYYY-MM-DD}.log",
rotation="00:00", # 每天午夜轮转
retention="30 days", # 保留30天
compression="gz", # 压缩格式
level="INFO"
)
logger.info("测试一下日志")
|
执行后,根据代码会得到两个日志文件,app.log, app_2025-08-01.log
3. 日志格式化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import sys
from loguru import logger
logger.remove()
# 自定义格式
logger.add(
sys.stderr,
format="<green>{time:YYYY-MM-DD HH:mm:ss}</green> | "
"<level>{level: <8}</level> | "
"<cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> | "
"<level>{message}</level>"
)
# 也可使用函数进行动态格式化
def custom_formatter(record):
if record["level"].no >= 40: # ERROR及以上
return "{time} | {level} | {thread} | {message}\n{exception}"
else:
return "{time} | {level} | {message}\n{exception}"
logger.add(sys.stderr, format=custom_formatter)
logger.info("测试一下日志")
|
会得到如下定义的输出结果:

4. 日志过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
| from loguru import logger
# 基于级别的过滤
def level_filter(level):
def is_level(record):
return record["level"].name == level
return is_level
logger.add(sys.stderr, filter=level_filter(level="WARNING"))
# 基于模块的过滤
logger.add("app.log", filter="my_module") # 只记录my_module的日志
logger.add("error.log", filter=lambda record: record["level"].no >= 40) # 只记录错误及以上日志
|
5. 结构化日志(JSON格式)
loguru默认提供支持json格式的序列化输出
1
2
3
4
5
6
| from loguru import logger
# JSON格式日志
logger.add(sys.stderr, serialize=True)
logger.info("测试一下日志")
|
得到如下输出:
1
| {"text": "2025-08-01 14:25:44.560 | INFO | __main__:<module>:8 - 测试一下日志\n", "record": {"elapsed": {"repr": "0:00:00.00 "seconds": 0.003698}, "exception": null, "extra": {}, "file": {"name": "demo.py", "path": "E:\\qiucao\\dev\\loguruDemo\\demo.py"}, "function": "<module>", "level": {"icon": "ℹ️", "name": "INFO", "no": 20}, "line": 8, "message": "测试一下日志", "module": " "name": "__main__", "process": {"id": 4580, "name": "MainProcess"}, "thread": {"id": 5680, "name": "MainThread"}, "time": {"repr": "2025-08-01 14:25:44.560271+08:00", "timestamp": 1754029544.560271}}}
|
6. 异常处理和调试
1
2
3
4
5
6
7
8
9
10
| from loguru import logger
# 控制诊断信息(生产环境应设为False)
logger.add("app.log", diagnose=False)
# 自动捕获异常
try:
result = 1 / 0
except ZeroDivisionError:
logger.exception("Division by zero occurred")
|
loguru 可以直接捕获异常,这里的diagnose 参数,还会在捕获异常时,自动记录局部变量的信息,便于我们进行调试(生产环境一般需要设置为False)
总结
以上就 loguru 这个库的用法总结,无论从配置的简便性,功能丰富程度,还是对自定义扩展、调试支持等多方面,都非常出色。
那么,写Python处理日志,就快快用起来吧~~
pytest中使用loguru的问题及解决
引语
上一篇文章,我们向大家推荐了python语言的一个第三方日志库loguru,使用非常简单且功能完备。文章参见【】
但对于我们做自动化测试,经常使用 pytest 框架的小伙伴来说,却有点小问题。就是 Pytest 内建的日志捕获机制是在标准库 logging 的基础上进行优化过的。 这样我们在使用 pytest 框架时,如果牵涉到 pytest 自身的日志机制,也就是pytest的内建fixture caplog实际使用的还是logging标准模块, 这里loguru 库定义的日志就难以发生作用。
当然,问题也不大,本文我们简单探讨下这个问题,并介绍下兼容方案。
Pytest 中的caplog
首先我们还是先来介绍下 Pytest 的日志
caplog是pytest提供的一个内置fixture,用于捕获和测试日志输出。
因为这个内置插件的作用,我们在执行pytest测试时,默认只会在用例存在失败时才会显示标准输出和logging模块及记录的日志信息。
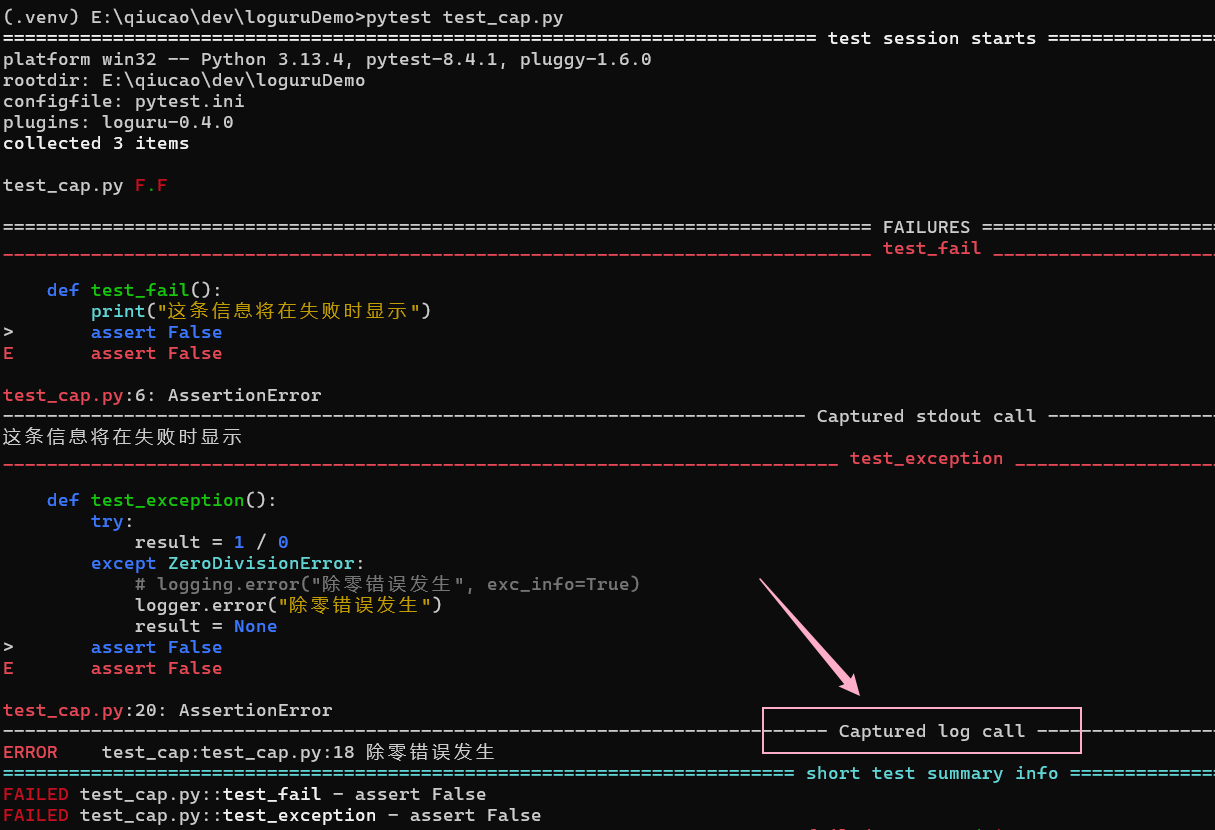
比如下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # test_cap.py
import logging
def test_fail():
print("这条信息将在失败时显示")
assert False
def test_pass():
print("这条信息成功时不显示")
assert True
def test_exception():
try:
result = 1 / 0
except ZeroDivisionError:
logging.error("除零错误发生", exc_info=True)
result = None
assert False
|
我们正常通过 pytest 执行的话,会看到下面这样的输出
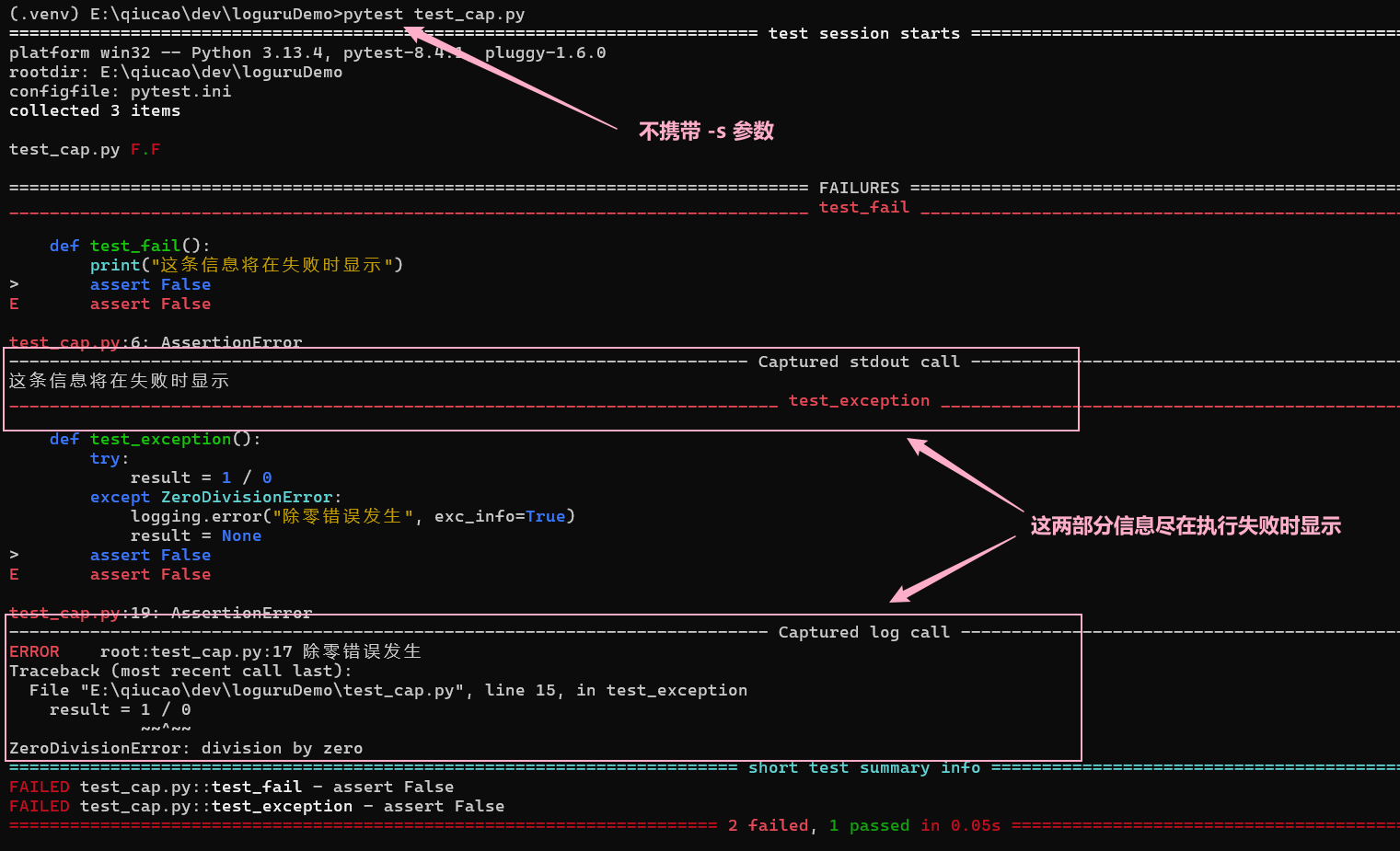
而如果我们将上面记录日志的部分修改为loguru库的日志写法的话
1
2
3
4
5
6
7
8
| def test_exception():
try:
result = 1 / 0
except ZeroDivisionError:
# logging.error("除零错误发生", exc_info=True)
logger.error("除零错误发生")
result = None
assert False
|
运行时能看到区别:
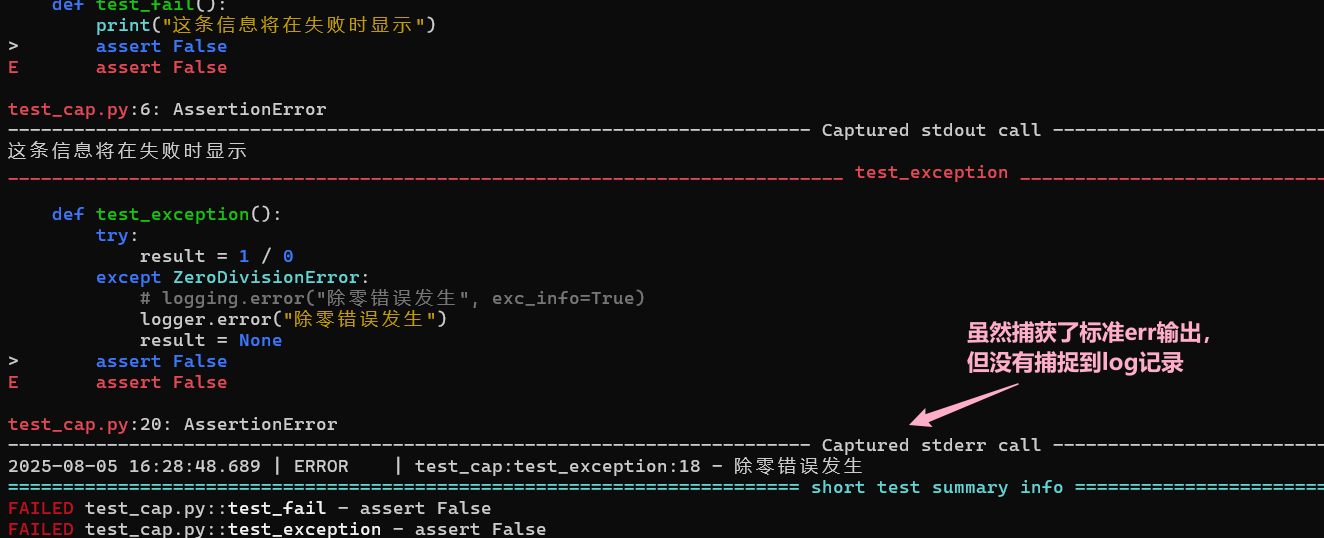
也就是 loguru 记录的日志,不能被 Pytest 的 caplog 获取。
这样自然也就不能使用 caplog 提供的一些api如 caplog.text, caplog.records, 为我们灵活利用 pytest 造成了一些阻碍
解决兼容问题
那要解决这个兼容问题,有多个方案,这里分享下我的验证
方案1:pytest-loguru
存在问题,当然可以先查一下社区有没有现成的解决方案, 然后发现有人已经提供了解决方案。就是 pytest-loguru 这个插件
通过下面命令安装即可:
pip install pytest-loguru
但我进行实测,发现windows系统上会报句柄错误
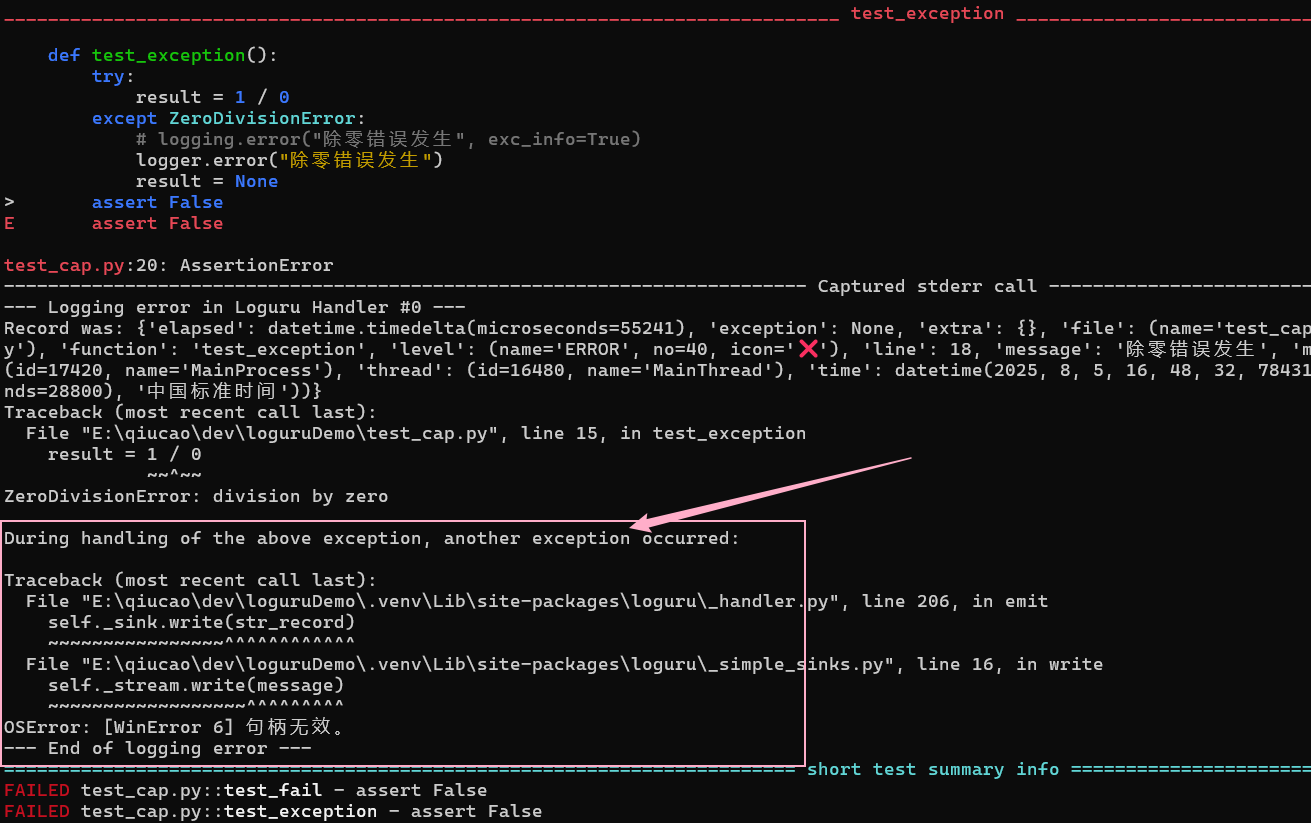
所以这里建议使用方案二解决。
方案二:loguru日志输出重定向到logging标准输出
可以利用 pytest 的 conftest.py 配置脚本,用下面的代码将 loguru 日志重定向到 logging
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| # conftest.py
import pytest
import logging
from loguru import logger
class SafePropagateHandler(logging.Handler):
def __init__(self):
super().__init__()
# 确保有一个基本的格式化器
self.setFormatter(logging.Formatter('%(levelname)s - %(message)s'))
def emit(self, record):
try:
# 获取标准logging的logger
std_logger = logging.getLogger(record.name)
# 确保logger有处理器
if not std_logger.handlers:
# 添加一个空处理器,避免"No handlers"警告
std_logger.addHandler(logging.NullHandler())
# 安全地处理记录
std_logger.handle(record)
except Exception:
# 如果传播失败,静默忽略,避免影响测试
pass
@pytest.fixture(scope="session", autouse=True)
def setup_safe_loguru_integration():
# 移除Loguru的默认处理器
logger.remove()
safe_handler = SafePropagateHandler()
# 添加传播处理器到Loguru
handler_id = logger.add(
safe_handler,
format="{message}", # 简化格式,避免重复
level="DEBUG",
backtrace=False,
diagnose=False,
catch=True # 捕获处理器中的异常
)
# 配置标准logging以避免冲突
logging.basicConfig(
level=logging.INFO,
format='%(levelname)s - %(message)s',
handlers=[logging.NullHandler()]
)
yield
# 清理
logger.remove(handler_id)
|
再次执行,可以看到caplog已经可以正常捕捉loguru记录的日志了
再吹一波python日志库loguru,和标准库logging全方位对比
之前的文章,我们推荐过python的第三方日志库loguru,主要是介绍了loguru的基本用法,本文我们从多个角度将它跟标准库 logging 作个详细对比,再直观了解下它的优点
配置复杂度对比
Python标准logging的配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import logging
# 标准logging需要多个步骤的配置
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 创建文件处理器
file_handler = logging.FileHandler('app.log')
file_handler.setLevel(logging.DEBUG)
# 创建格式化器
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s')
# 设置格式化器
console_handler.setFormatter(console_formatter)
file_handler.setFormatter(file_formatter)
# 添加处理器
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# 现在才能开始使用
logger.info("配置完成,开始记录日志")
|
Loguru的配置:
1
2
3
4
5
6
7
| from loguru import logger
# Loguru一行代码即可完成相同功能
logger.add(sys.stdout, level="INFO", format="{time} - {name} - {level} - {message}")
logger.add("app.log", level="DEBUG", format="{time} - {name} - {level} - {file}:{line} - {message}")
logger.info("配置完成,开始记录日志")
|
优势对比:
- 标准logging:需要创建logger、handler、formatter等多个对象,并进行多层配置
- Loguru:通过简单的
add()方法即可完成所有配置,代码量减少70%以上
API简洁性对比
Python标准logging的API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import logging
# 需要导入多个模块和类
import logging.handlers
import logging.config
# 不同级别需要不同的方法调用
logger.debug("Debug message")
logger.info("Info message")
logger.warning("Warning message")
logger.error("Error message")
logger.critical("Critical message")
# 异常记录需要单独处理
try:
1 / 0
except Exception as e:
logger.error("An error occurred", exc_info=True)
|
Loguru的API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from loguru import logger
# 统一的API,更直观的方法名
logger.trace("Trace message") # 比debug更详细
logger.debug("Debug message")
logger.info("Info message")
logger.success("Success message") # 独有的成功级别
logger.warning("Warning message")
logger.error("Error message")
logger.critical("Critical message")
# 异常记录极其简单
try:
1 / 0
except Exception:
logger.exception("An error occurred") # 自动包含异常信息
|
优势对比:
- 标准logging:API相对繁琐,异常处理需要额外参数
- Loguru:API设计更加人性化,提供SUCCESS级别,异常处理更简洁
功能特性对比
| 功能特性 | Python标准logging | Loguru | 优势说明 |
|---|
| 日志轮转 | 需要TimedRotatingFileHandler或RotatingFileHandler | 内置支持,一行代码配置 | Loguru配置简单,支持更多轮转策略 |
| 日志压缩 | 不支持,需要手动实现 | 内置支持多种压缩格式 | Loguru自动处理,节省存储空间 |
| 日志过滤 | 需要创建Filter类 | 支持函数、字符串、字典等多种过滤方式 | Loguru更灵活,代码更少 |
| 结构化日志 | 不支持原生JSON格式 | 内置JSON序列化支持 | Loguru更适合现代日志分析系统 |
| 颜色支持 | 需要第三方库如colorama | 内置终端颜色支持 | Loguru开箱即用,视觉效果更好 |
| 上下文信息 | 需要手动使用LoggerAdapter | 通过bind()方法轻松实现 | Loguru更直观,功能更强大 |
| 异常诊断 | 基本的异常信息 | 详细的变量值显示和调用栈 | Loguru调试效率更高 |
代码示例:
标准logging实现日志轮转:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import logging
import logging.handlers
import os
# 创建轮转文件处理器
rotating_handler = logging.handlers.RotatingFileHandler(
'app.log',
maxBytes=10*1024*1024, # 10MB
backupCount=5
)
# 需要手动处理压缩
def compress_old_logs():
# 复杂的压缩逻辑...
pass
logger.addHandler(rotating_handler)
|
Loguru实现日志轮转:
1
2
3
4
5
6
7
8
9
| from loguru import logger
# 一行代码搞定轮转和压缩
logger.add(
"app.log",
rotation="10 MB", # 文件大小轮转
retention="10 days", # 保留10天
compression="zip" # 自动压缩
)
|
使用体验对比
Python标准logging的痛点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import logging
# 痛点1:全局配置影响所有模块
logging.basicConfig(level=logging.DEBUG) # 会影响整个程序
# 痛点2:重复日志问题
logger1 = logging.getLogger('app')
logger2 = logging.getLogger('app.module')
# 如果配置不当,容易出现重复日志
# 痛点3:格式化字符串需要使用%
logger.info("User %s logged in from %s", username, ip_address)
# 不如f-string直观
# 痛点4:难以获取调用者信息
# 需要复杂的格式化字符串才能显示文件名和行号
|
Loguru的解决方案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from loguru import logger
# 优势1:单例模式,避免配置混乱
# 无需担心多个logger实例的配置问题
# 优势2:自动避免重复日志
# 智能的处理器管理,不会出现重复输出
# 优势3:支持现代字符串格式化
logger.info(f"User {username} logged in from {ip_address}")
# 也支持{}格式化
logger.info("User {} logged in from {}", username, ip_address)
# 优势4:自动包含丰富的上下文信息
# 默认显示时间、级别、模块、函数、行号等
|
性能和内存使用对比
性能测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import time
import logging
from loguru import logger
# 测试标准logging性能
def test_standard_logging():
std_logger = logging.getLogger('test')
std_logger.setLevel(logging.DEBUG)
handler = logging.StreamHandler()
handler.setLevel(logging.DEBUG)
std_logger.addHandler(handler)
start = time.time()
for i in range(10000):
std_logger.debug(f"Test message {i}")
end = time.time()
return end - start
# 测试Loguru性能
def test_loguru():
logger.remove()
handler_id = logger.add(sys.stderr, level="DEBUG")
start = time.time()
for i in range(10000):
logger.debug(f"Test message {i}")
end = time.time()
logger.remove(handler_id)
return end - start
|
性能对比结果:
- 标准logging:在简单场景下性能略好,但功能有限
- Loguru:在启用高级功能(如异步、格式化)时性能接近标准logging,但功能更强大
内存使用对比:
- 标准logging:每个logger实例占用较多内存
- Loguru:单例模式,内存使用更高效
迁移成本对比
从标准logging迁移到Loguru:
1
2
3
4
5
6
7
8
9
10
| # 原有代码
import logging
logger = logging.getLogger(__name__)
logger.info("This is a log message")
# 迁移后代码
from loguru import logger
logger.info("This is a log message") # API几乎完全兼容
|
迁移优势:
- API兼容性:Loguru的API设计与标准logging相似,学习成本低
- 渐进式迁移:可以在项目中同时使用两者,逐步迁移
- 向后兼容:Loguru提供了与标准logging的集成方案
总结
| 对比维度 | Python标准logging | Loguru | 推荐选择 |
|---|
| 学习曲线 | 陡峭,需要理解多个概念 | 平缓,直观易用 | Loguru |
| 配置复杂度 | 高,需要多个步骤 | 低,一行代码搞定 | Loguru |
| 功能完整性 | 基础功能,需要扩展 | 开箱即用的高级功能 | Loguru |
| 代码简洁性 | 冗长,模板代码多 | 简洁,表达力强 | Loguru |
| 调试友好性 | 一般 | 优秀,详细信息丰富 | Loguru |
| 性能 | 略好(简单场景) | 接近,功能更强大 | Loguru |
| 社区支持 | 官方支持,历史悠久 | 活跃社区,快速迭代 | Loguru |
结论:
Loguru在几乎所有的对比维度上都优于Python标准logging库。它不仅大大简化了日志配置的复杂性,还提供了更丰富的功能和更好的用户体验。对于新项目,强烈推荐直接使用Loguru;对于现有项目,也可以考虑逐步迁移到Loguru以提升开发效率和日志管理能力。
