前言
随着 AI 大模型的爆发,提示词工程(prompt engineering ) 一度是用户应用 AI ,发挥 AI 能力最重要、也最应该掌握的技术。 但现在,在 “提示词工程”的基础上,一个更宽泛也更强力的演化概念被提出,也就是本文我们要介绍的 “上下文工程(Context Engineering)”
特别是今年以来,随着 AI Agent的爆发,在应用 AI 时,将哪些信息有效传递给 AI “有限的记忆空间”变得越来越重要。很多时候,调用 AI Agent 效果不佳,并不是大模型本身的能力不佳,更多是上下文的质量有所欠缺。

提示词工程的局限性
提示词工程 通过优化输入给模型的文本,可以优化模型的输出质量。
但随着越来越多Agent的加入,以及应用场景的复杂化,仅依靠提示词,已经很难让大模型有效完成 越来越复杂的任务。
比如要完成一个AI智能测试用例系统,在利用大模型的过程中,还需要如下信息:
- 原始的需求文档、接口文档信息
- 系统的架构设计、数据库、系统框架
- 各种应用接口的状态
- 和用例管理、文档管理、自动化测试等外部工具的调用。
这些要求,仅仅通过向大模型和对应的Agent传递提示词,已经很难完成。
这也就是提示词工程最大的局限性:缺乏上下文理解与状态管理能力。
何为上下文工程?
要理解“上下文工程”,先要明确,何为上下文?
相比提示词(prompt),上下文(context) 并不仅仅是我们传递给大模型的单一的提示词,可以认为是大模型在返回结果前,它所看到的一切信息
总结来说,上下文 包含如下一些内容:
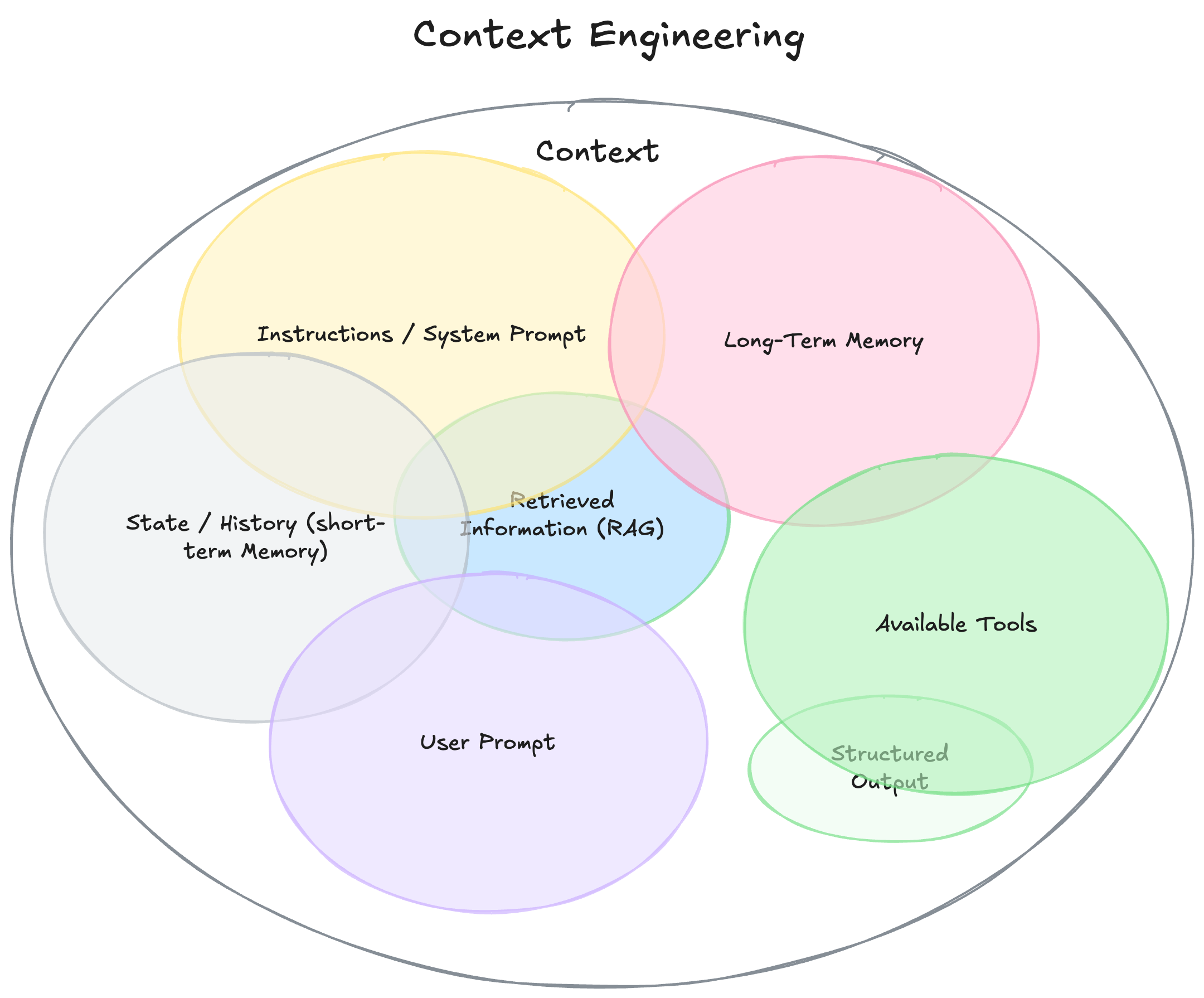
背景介绍/系统提示词(**Instructions / System Prompt)
这是用户和大模型在整个会话期间的初始约定。包括约定背景、大模型充当的角色、它的期望行为等。可以通过一些示例和规则定义进行约束。
比如我们之前介绍过的通过AI来编写测试用例生成工具,系统提示词可以约定
| |
用户提示词(User Prompt)
用户提示词,相对系统提示词是作用于整个会话来说,是用户当前告知AI大模型的指令或提出的问题。
它其实就是之前说到提示词工程的主要应用,通过优化用户提示词的编写,可以和AI完成更有效的沟通。
如上例,在AI辅助开发的过程中,我们向AI提交的具体开发任务。
| |
状态及对话历史(短期记忆)
主要指在当前会话过程中,产生的对话历史和生成的中间结果。
比如在脚本开发过程中,完成的代码文件,程序运行出现的错误等信息。
长期记忆
这里包含更持久的背景知识,包括之前多次的对话信息收集,如已学习到的用户偏好、过去项目的总结,或者由用户告知、以备将来使用的信息。
如上述开发过程,包括项目的需求文档、架构设计、数据库结构、测试数据等信息。
RAG(检索增强生成,Retrieval-augmented generation )
RAG是通过向量数据库、知识库检索等方式,为模型提供额外的相关信息。它让模型能够在回答问题时参考最新的、相关的上下文,而不是依赖于训练时的知识。
结构化输出
为了让模型输出更加可控和可解析,并便于 Agent 的处理,我们通常需要定义输出格式,例如 JSON Schema 或特定字段结构,提高结果一致性。
例如之前的系统提示词,明确要求模型输出一个包含相关字段的 JSON 对象。
可用工具
通过 Agent 或 MCP, 大模型可以调用工具能力,比如自动化测试工具(Playwright)、CI/CD持续集成系统等等
使用上下文工程的关键
✅ 上下文不是一个字符串,而是一个系统
上下文是运行在 LLM 调用之前的系统逻辑,它动态组装所有相关信息,而不是一个静态模板。
✅ 上下文是动态的
每次调用 LLM 之前,都要根据当前任务动态准备上下文,例如注入当前日期、用户偏好、项目配置等。
✅ 上下文强调信息与工具的精准匹配
不能简单堆砌信息,而是要在合适的时间提供最相关的知识和能力。例如,只在需要时注入数据库连接工具。
✅ 格式决定输出质量
如何呈现信息很重要。简洁的摘要比原始数据更好,清晰的工具 schema 比模糊的说明更有用。
结语
科技行业,每隔一段时间就会产生新名词、新概念,大家已经见怪不怪。“上下文工程” 虽然概念上和 ”提示词工程“ 有所区别,但它们的出发点和目标其实是一致的,就是让用户和AI实现更有效的沟通。本质上跟我们前文 【】中的解释是一脉相承的。
它其实并不是一个新兴的技术,我们把它理解成使用AI的技巧就好!