前言
AI已经越来越深入地走入我们的实际工作,在软件测试领域,和AI相关的新测试工具、方法也层出不穷。在之前我们介绍过结合 mcp server 实现 AI 驱动测试的案例,本文我们将介绍一个近期崭露头角的国产AI测试工具 Midscene.js

Midscene.js简介
MidScene.js 是由字节跳动 web-infra 团队推出的一个开源 ai 自动化测试工具,基于多模态大模型,通过针对页面的智能视觉解析来理解我们的自然语言指令,并进一步完成自动化操作。可以显著降低编写自动化测试脚本的复杂性,并更好适应页面结构和元素的变化,使自动化测试脚本的稳定性也有较大提升。
官网地址: https://midscenejs.com/
Midscene工作原理
和之前我们介绍 mcp server 时,利用通用大模型来理解页面并调用本地工具能力进行扩展不同,Midscene使用多模态大模型如 ChatGPT-4o,qwen-vl, 字节的 UI-TARS等,也就是能支持视觉输入的大模型来理解页面,更接近我们进行实际功能测试的场景。
MidScene会首先获取页面当前截图和具体的页面结构信息,再和用户指令一起提交给大模型,由大模型判断出需要操作的页面控件位置,并进行下一步动作。
以在待办页面任务框中输入 “今天学习Playwright”为例:
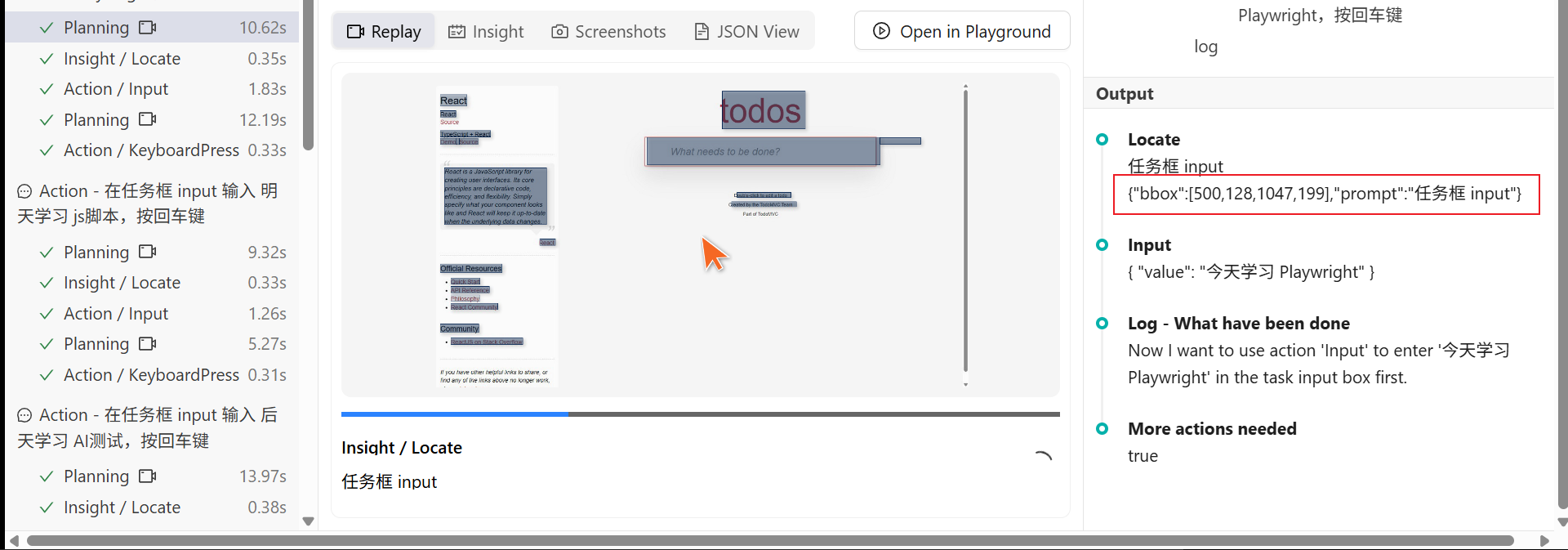
MidScene的内部操作大致如下:
- 获取用户指令 “在任务框输入 学习Playwright,按回车键”
- MidScene截图,获取页面整体元素结构
- 提交大模型完成页面特征提取
- 获取大模型分析结果,确定下一步操作类型(Tap)和控件的具体位置(坐标)
- 规划下一步操作
- 完成执行
大模型的选择
从以上Midscene的原理分析,MidScene 主要依赖多模态大模型的如下能力
- 理解截图和 规划 操作步骤的能力。
- 给出指定元素的坐标信息(Visual Grounding)的能力。
支持以上能力的大模型,目前官网提供的支持包括如下几种:
- OPENAI GPT-4o
- 阿里 Qwen-2.5-VL
- 字节 UI-TARS
- 字节火山引擎 Doubao-1.5-thinking-vision-pro
- Google Gemini-2.5-Pro
从工作原理上,需要提供给大模型包括截图和页面结构等信息,对大模型的Token消耗还是比较可观。从官方的评估,每个操作通常都要至少数千Token的消耗。而其中性价比较好的大模型,官方推荐的QWen-VL。
Chrome插件方式使用
零代码的Chrome插件方式,可以帮助我们快速理解MidScene的应用。
通过Chrome的插件商店可以直接安装 Midscene插件
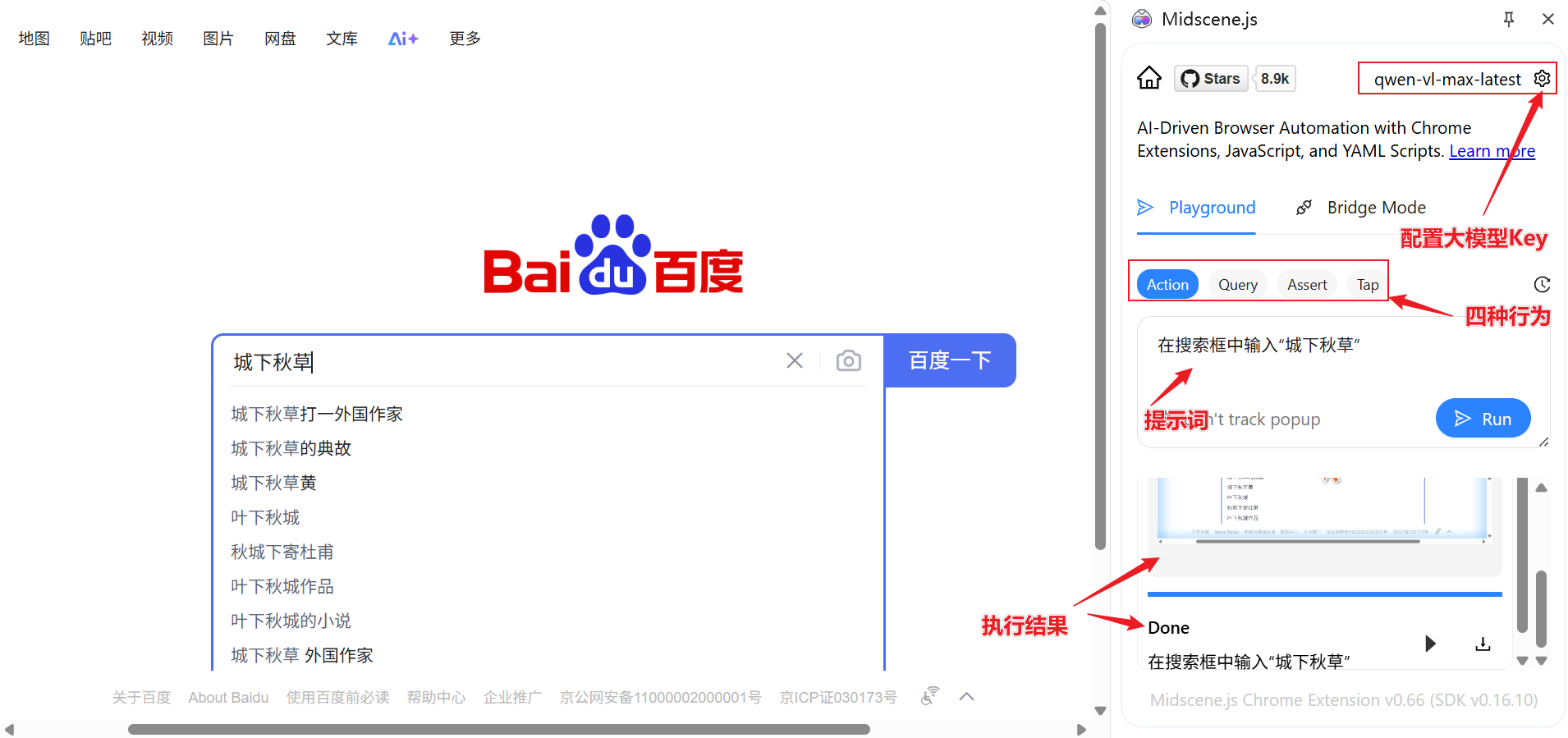
配置大模型
启用插件后,需要配置使用的大模型。这里我们使用对token消耗比较少的阿里千问多模态模型qwen-vl-max-latest, 通过阿里云百炼平台申请对应的API Key即可,现在申请还赠送100W Token额度。

完成申请后,在插件的模型配置界面中配置对应的大模型参数,qwen模型需要配置以下四个参数
1
2
3
4
| OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY="sk- your API KEY"
MIDSCENE_MODEL_NAME="qwen-vl-max-latest"
MIDSCENE_USE_QWEN_VL=1
|
操作浏览器
接下来就可以在插件界面中体验Midscene对浏览器的操控了,这里主要支持四种行为:
- Action:对应AI自动规划操作,Midscene会自动规划操作步骤并执行。更智能,但速度较慢,效果依赖大模型的质量。
- Query:直接从 UI 提取数据,并借助多模态 AI 的推理能力,实现智能提取
- Assert:通过自然语言描述一个断言条件,让 AI 判断该条件是否为真
- Tap:对应页面点击的即时操作,Midscene会直接执行,大模型只负责底层如元素定位等任务。效率更高,适合已确定要执行的操作时使用
我们可以用接近自然语言的AI提示词输入提示词指令,针对不同的行为模式,插件会驱动浏览器完成不同的操作,并反馈操作结果。
具体执行过程也可参见下方视频演示。
脚本集成
除了通过浏览器插件调用Midscene,更推荐的方法是通过测试框架的脚本集成Midscene能力。
通过脚本集成,同样需要配置相关模型调用参数,和插件中配置的相关变量值一样,只是需要将相关变量配置为系统环境变量
因为 Midscene 是基于JS的工具,这里的和测试框架集成,也是需要支持JS。这里以 Playwright 为例
安装
首先自然需要具备 Playwright 框架,进入项目目录,初始化并安装Playwright,然后安装Midscene
1
2
3
|
npm init playwright@latest
npm install @midscene/web --save-dev
|
playwright框架配置
在 playwright.config.ts 文件中配置框架本身的测试发现目录和测试脚本,加载环境变量以及浏览器类型,执行策略等基础配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| import { defineConfig, devices } from "@playwright/test";
import dotenv from "dotenv";
/* 通过dotenv从.env文件中加载环境变量 */
dotenv.config();
export default defineConfig({
testDir: "./e2e",
testMatch: "**/*.spec.ts",
timeout: 10 * 60 * 1000,
/* Run tests in files in parallel */
fullyParallel: false,
/* Fail the build on CI if you accidentally left test.only in the source code. */
forbidOnly: Boolean(process.env.CI),
/* Retry on CI only */
retries: process.env.CI ? 2 : 0,
/* Opt out of parallel tests on CI. */
workers: process.env.CI ? 1 : undefined,
/* Reporter to use. See https://playwright.dev/docs/test-reporters */
reporter: [["line"], ["@midscene/web/playwright-report"]],
/* Shared settings for all the projects below. See https://playwright.dev/docs/api/class-testoptions. */
use: {
/* Base URL to use in actions like `await page.goto('/')`. */
// baseURL: 'http://127.0.0.1:3000',
/* Collect trace when retrying the failed test. See https://playwright.dev/docs/trace-viewer */
trace: "on-first-retry",
},
/* Configure projects for major browsers */
projects: [
{
name: "chromium",
use: { ...devices["Desktop Chrome"] },
},
],
});
|
测试脚本
通过单独的fixture脚本引入Midscene库
fixture.ts
1
2
3
4
5
6
7
8
9
10
11
12
13
| import { test as base } from '@playwright/test';
import type { PlayWrightAiFixtureType } from '@midscene/web/playwright';
import { PlaywrightAiFixture } from '@midscene/web/playwright';
export const test = base.extend<PlayWrightAiFixtureType>(PlaywrightAiFixture({
waitForNetworkIdleTimeout: 10000, // 可选, 交互过程中等待网络空闲的超时时间, 默认值为 2000ms, 设置为 0 则禁用超时
}));
|
编写脚本测试 https://todomvc.com/ 待办清单示例项目,通过 .ai、.aiTap、 .aiQuery、.aiAssert等API方法,对应前面说到的四种典型操作。
todo_spec.ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import { expect } from "@playwright/test";
import { test } from "./fixture";
test.beforeEach(async ({ page }) => {
await page.goto("https://todomvc.com/examples/react/dist/");
});
test("ai todo - Chinese Prompt", async ({ ai, aiQuery, aiAssert, aiTap }) => {
// .ai - 通用 AI 操作方法
await ai("在任务框 input 输入 今天学习 Playwright,按回车键");
await ai("在任务框 input 输入 明天学习 js脚本,按回车键");
await ai("在任务框 input 输入 后天学习 AI测试,按回车键");
await ai("将鼠标移动到任务列表中的第二项");
await aiTap("第二项任务右边的删除按钮");
// .aiTap - 指定操作类型
await aiTap("第二条任务左边的勾选按钮");
await aiTap("任务列表下面的 completed 状态按钮");
// .aiQuery - 页面信息提取操作
const list = await aiQuery("string[], 完整的任务列表");
expect(list.length).toEqual(1);
// .aiAssert - 断言操作
await aiAssert('列表下方有一个区域显示有 "1 item left"');
});
|
执行脚本:
1
| npx playwright test --headed
|
执行过程可以参见我录制的视频
【】
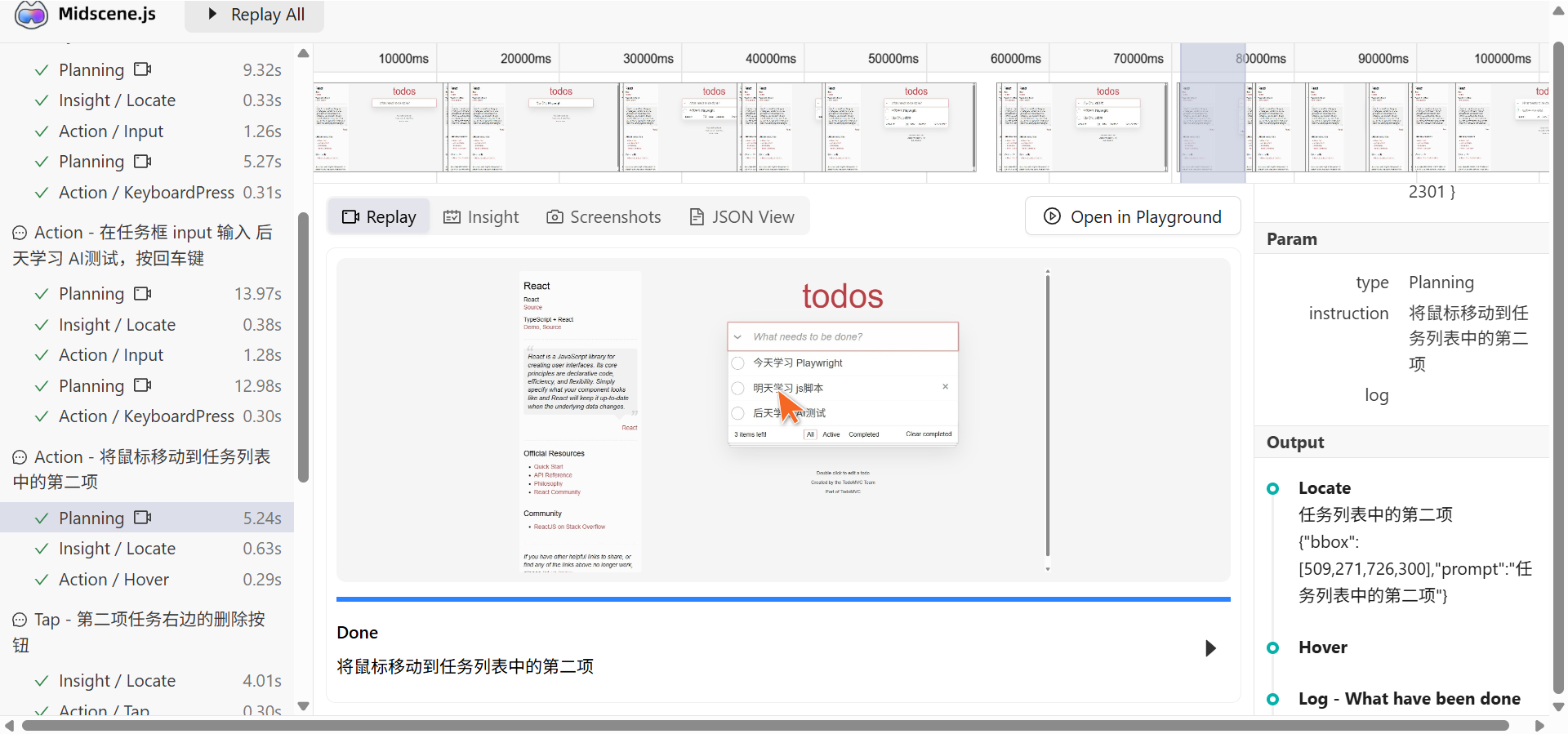
可视化结果报告
报告是Midscene的一大亮点,通过这个报告可以回看整个执行过程,并详细显示AI的空间判断过程和具体操作细节,便于调试和优化脚本。
YAML文件驱动
除了通过测试框架脚本的集成方法,Midscene也支持直接通过YAML文件编写测试脚本,实现无代码的脚本驱动,类似于传统自动化的关键字驱动方式。
这种方式,本质上其实还是将对应关键转化为 Midscene 支持的相关API来进行驱动。
类似如下的格式, 操作天气网站:
1
2
3
4
5
6
7
8
9
10
11
12
| web:
url: https://www.bing.com
tasks:
- name: 搜索天气
flow:
- ai: 搜索 "今日天气"
- sleep: 3000
- name: 检查结果
flow:
- aiAssert: 结果中展示了天气信息
|
运行yaml格式脚本,需要安装Midscene的命令行支持
1
2
3
4
| npm install @midscene/cli --save-dev
# 执行
npx midscene ./weather.yaml
|
MCP方式
除了上述方式之外,Midscene也提供了作为本地MCP server方式。这种方式,其实是将MidScene的Chrome插件作为本地能力封装到MCP中,再通过大模型结合mcp server的方式完成浏览器驱动。
关于 mcp server的介绍和使用,可以参考我之前的相关文章 【】
mcp server 配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
"mcpServers": {
"mcp-midscene": {
"command": "npx",
"args": ["-y", "@midscene/mcp"],
"env": {
"MIDSCENE_MODEL_NAME": "REPLACE_WITH_YOUR_MODEL_NAME",
"OPENAI_API_KEY": "REPLACE_WITH_YOUR_OPENAI_API_KEY",
"MCP_SERVER_REQUEST_TIMEOUT": "800000"
}
}
}
}
|
当前版本的局限
虽然Midsence工具已经展现出不俗的潜力,目前也还在持续更新和迭代中,但在实用上还是具有不少缺陷,主要表现在:
- 交互类型有限:目前仅支持点击、拖拽(只在 UI-TARS 模型中支持)、输入、键盘和滚动操作。
- 稳定性风险:AI 模型的返回值不能保证 100% 准确。对提示词的编写要求较高
- 元素识别能力:部分大模型在元素识别上的能力不太好,比如iframe、canvas等元素的交互。而且对于Chrome的原生控件如弹出提示、右键菜单等还不能支持。
- 成本较高:基于视觉识别方式,对Token的消耗比较可观,如果使用付费大模型,成本比较高昂。
但瑕不掩瑜,Midscene在UI自动化测试借助AI能力的提升上,已经迈出了坚实的一步!后续我们还会持续关注其进一步发展!
参考阅读:
【】
【】
进群,大纲
