
前言
很多刚接触 AI 辅助编程的小伙伴应该都听说过 Cursor 的强大,对初学者而言,免费版Cursor的免费额度也足够让大家体验它的强悍能力。

可是在实际应用过程中,从我的实际经验,如果只是把它当作一个沟通对象,像和人沟通那样来完成开发任务,却会浪费大量时间在纠正它的理解偏差,而且极大概率在某一次对话后,把原来的成果改得面目全非,大量努力付诸东流。
Cursor的12条军规
其实 Cursor 是否能更有效地发挥作用,跟它的使用方式有很大关系。Cursor的首席设计师 Ryo Lu 早前曾在 X 上给出善用 Cursor 的12条军规:
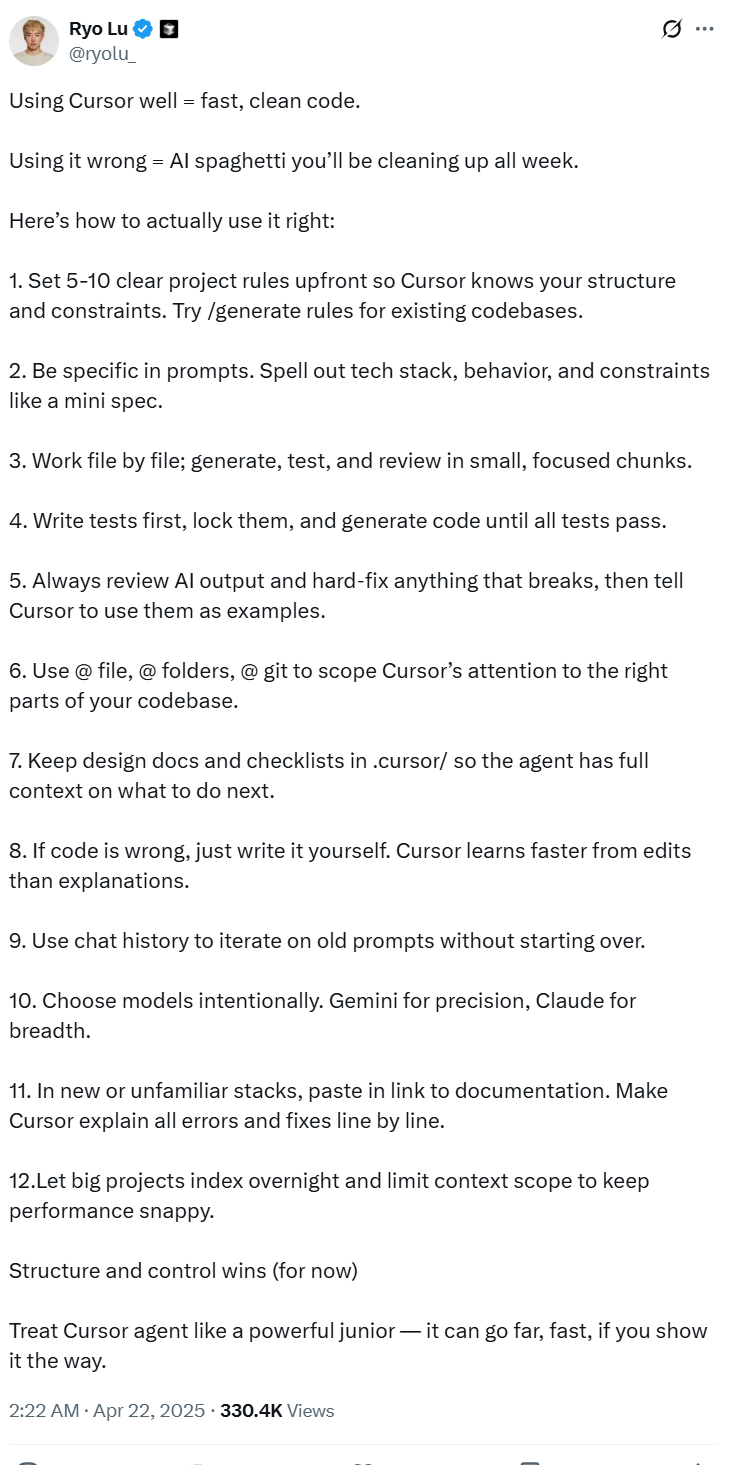
- 明确项目规则: 在项目开始前,设置5-10条清晰的项目规则,让Cursor了解你的代码结构和约束。对于现有代码库,可以尝试使用
/generate rules命令来生成规则。 - 具体化提示: 在提示中要非常具体,详细说明技术栈、期望行为和限制,就像编写一个迷你规范。
- 按文件操作: 每次处理一小部分,生成、测试并审查,保持专注。
- 测试先行: 优先编写测试,锁定测试用例,然后生成代码直到所有测试通过。
- 严格审查与修正: 始终审查AI的输出,并手动修复任何错误,然后将这些修正作为示例告知Cursor。
- 限定作用域: 使用
@ file,@ folders,@ git等命令来将Cursor的注意力限制在代码库的特定部分。 - 提供完整上下文: 将设计文档和清单保存在
.cursor/目录下,以便Cursor代理能够充分理解下一步需要做什么。 - 直接修改错误代码: 如果生成的代码有误,直接手动修改。Cursor从编辑中学习的速度比从解释中学习更快。
- 利用聊天历史: 使用聊天历史来迭代旧的提示,而无需从头开始。
- 明智选择模型: 根据需求有目的地选择模型。例如,Gemini适用于追求精确性,而Claude适用于需要更广泛知识的场景。
- 处理新栈或不熟悉栈: 在处理新或不熟悉的技术栈时,粘贴相关文档链接。让Cursor逐行解释所有错误和修复方法。
- 优化大型项目性能: 对于大型项目,让其在夜间进行索引,并限制上下文范围以保持性能的流畅性。
| |
测试开发如何善用Cursor?
而作为一个测试开发或自动化测试工程师,我们在编写相关测试脚本或工具时,如何善用 Cursor 更好帮助我们提升效率和产出呢?本文我们参照以上 12 条规则,总结相关的实践指南。
初始化与上下文构建——将Cursor训练成“测试领域专家”
在项目启动或介入初期,首要任务是让Cursor充分理解当前测试环境的规范与约束。高质量的上下文输入,是高质量代码输出的前提。
明确项目测试规则与约定 (规则1)
在自动化测试项目中,代码规范、框架选型和设计模式的统一至关重要。基于规则1:明确项目规则 ,我们可以利用.cursor/rules.md文件,将这些隐性的团队知识显性化,为Cursor提供一份清晰的行动纲领 。而对于存量项目,还可先使用/generate rules命令初步提炼规则,再进行人工增补。
实践案例:在一个基于Python Flask的Web项目中,测试技术栈为Pytest与Selenium。可以在.cursor/rules.md中定义如下规则:
| |
提供详尽的指令以模拟“测试场景” (规则2)
与AI的交互质量直接决定输出代码的质量。自动化测试的指令尤其需要精确性,因为它必须完整描述被测功能、输入数据、预期行为乃至异常路径。
实践案例:为用户登录功能编写集成测试。
- 效果不佳的指令:
写一个登录测试。 - 结构清晰的指令:
| |
迭代式开发与修正——实现“测试代码的持续集成”
将复杂的测试任务分解,通过“生成-验证-修正”的敏捷循环进行开发,是确保代码质量和项目进度的有效策略。
小步快跑,增量验证 (规则3)
应规避一次性生成整个复杂模块所有测试的诱惑。
正确的做法是将任务分解为最小可验证单元,逐个击破。
例如,在为一组RESTful API编写测试时,应按“创建用户 -> 获取用户 -> 更新用户 -> 删除用户”的逻辑顺序,逐一生成和验证测试代码
这种方式有助于快速定位问题,避免错误的累积。
测试驱动开发(TDD)的应用 (规则4)
测试驱动开发是保障代码质量的经典模式,Cursor可以成为该模式的强大加速器。工程师先定义函数的预期行为(即编写测试用例),再让AI生成满足这些测试的实现代码。
实践案例:实现一个折扣计算函数calculate_discount(price, discount_rate)。
- 定义测试: 首先要求Cursor:
生成一个Pytest测试用例,用于测试calculate_discount函数。当price=100, discount_rate=0.1时,预期返回值为90;当discount_rate为负数时,应抛出ValueError异常。 - 生成实现: 在测试代码
test_calculate_discount.py生成后,运行它(此时会失败),然后对Cursor发出新指令:请根据刚才生成的测试用例,实现calculate_discount函数的功能。 - 验证闭环: Cursor生成函数实现后,再次运行测试,直至全部通过。
主动纠正,教学相长 (规则5)
需要注意的是,AI生成的代码并非永远正确,而工程师的审查和修正是最后一道防线。直接在代码中修正错误,是训练Cursor最有效的方式,远胜于用自然语言向其解释。
实践案例:
比如Cursor在生成的UI测试中,使用了一个不稳定且错误的XPath定位器//button[@id='submit']。在测试运行失败后,我们可以直接手动将其修改为正确的定位器,例如 //input[@value='Login']。修正后,可以在聊天中备注一句以强化其学习:“我已修正登录按钮的定位器,新的定位器更准确。请在后续任务中参考此模式。” 。
精细化管理——实现“测试资源的智能调度”
在大型项目中,如何让Cursor聚焦于正确的信息,是决定其效率和相关性的关键。
精准限定上下文范围 (规则6)
在庞大的代码库中,测试任务往往只与特定模块或服务相关。通过使用@folders或@file命令,可以显著缩小Cursor的分析范围,让其专注于必要的上下文。
实践案例:
当为user_service微服务编写API测试时,所有相关代码位于services/user_service/目录。此时,应在提问前先输入@folders services/user_service/,然后再描述具体的测试需求。
沉淀项目知识以辅助决策 (规则7)
可以将测试策略、UI定位器优先级、数据模拟规范等关键信息沉淀为文档,并存放于.cursor/目录中。这相当于为Cursor提供了一套“项目级知识库”。
实践案例:
创建.cursor/ui_locators_priority.md文件,内容为:“UI元素定位优先顺序:ID > Name > CSS Selector > XPath”。在提问时便可引用:请参考.cursor/ui_locators_priority.md中的策略,为注册页面的‘提交’按钮生成Selenium定位代码。。
问题解决与效率优化——化身“测试效率加速器”
掌握高级用法,能进一步将Cursor从日常助手,转变为解决复杂问题和加速学习的利器。
智能选择AI模型 (规则10)
不同的AI模型具有不同的能力侧重。根据测试任务的特性选择合适的模型,可以事半功倍。
- Gemini (精度优先):适用于生成语法要求严格的单元测试、算法校验、或使用特定框架(如React Testing Library)的精细化测试代码。
- Claude (广度优先):更适合需要理解大量上下文的场景,如根据API文档生成全面的集成测试、设计端到端(E2E)测试场景,或在不熟悉的代码库中探索和建议测试点。
利用文档快速掌握新技术 (规则11)
当团队引入新的测试框架(如Playwright)时,工程师可以利用Cursor快速跨越学习曲线。
实践案例: 直接向Cursor提供Playwright官方文档链接,并要求其生成示例代码。当生成的代码运行出错时,可以粘贴错误信息并提问:“这是运行Playwright脚本时出现的错误,请根据官方文档逐行解释错误原因,并提供修复建议。”。
限制上下文范围 (规则12)
当项目代码量比较大时,通过过夜索引,并限制上下文范围。
实践案例:
在处理大型测试项目时,允许Cursor在后台处理索引,到第二天再进行具体的代码生成,从而保持性能流畅。
| |
总结
对于我们实际工作而言,成功运用Cursor的本质,是一个从“指令下达者”转变为“智能协作者”和“知识引导者”的过程。着眼点在于突出其 智能协作、知识沉淀和效率提升 的系统性作用。