
前言
在之前的文章 【】我们了解了字节跳动推出的AI测试工具 Midscene.js, 不管是智能解析项目,测试执行还是最后的报告生成都颇为亮眼,而且除了基于浏览器的web应用,还支持了Android应用的自动化。
那么这个项目具体是如何利用 AI 智能完成测试执行任务的呢? 本文我们就结合 Midscene.js 的开源项目源码,对该项目的实现,以及对大模型的应用进行深入分析。
项目整体架构
通过项目源码的分析,该项目的总体架构可以用下图概括:
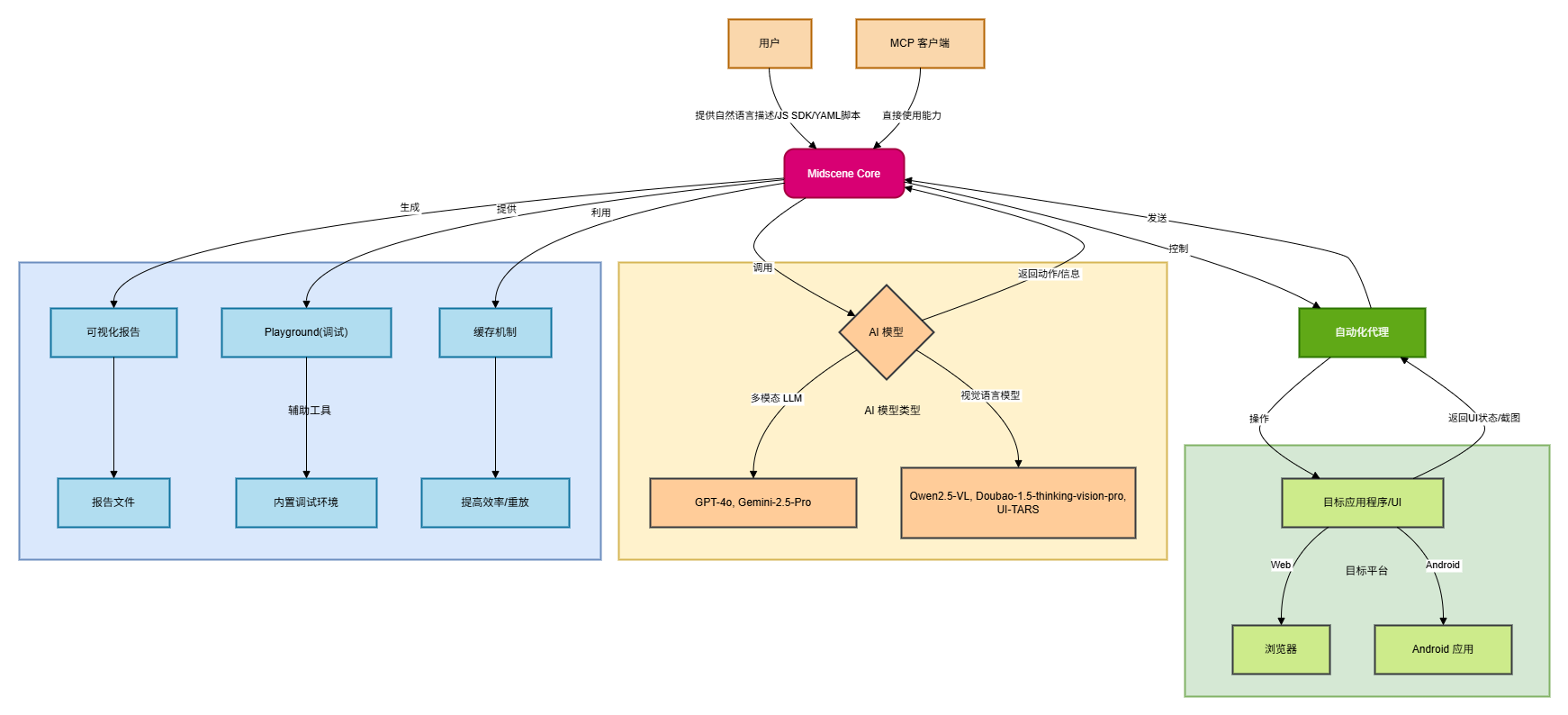
用户: 用户是Midscene的起点,通过自然语言描述、JavaScript SDK 或 YAML 脚本来定义自动化任务和目标。
MCP 客户端 (MCP Clients): Midscene还支持其他MCP客户端直接使用其能力,这表明它可能有一个API或集成点供其他系统调用。
Midscene Core: 这是Midscene的核心逻辑层。它负责解析用户的指令,与AI模型交互,并协调自动化代理来执行操作。它也管理报告生成和缓存。
AI 模型: Midscene支持多种AI模型,包括:
多模态 LLM (Multimodal LLM):如 GPT-4o, Gemini-2.5-Pro,用于理解更复杂的指令和上下文。
视觉语言模型 (Visual-Language Models):如 Qwen2.5-VL, Doubao-1.5-thinking-vision-pro, UI-TARS,特别推荐用于UI自动化,因为它们能更好地理解视觉信息。 AI模型接收来自Midscene Core的请求,并返回执行动作或获取信息的指令。
自动化代理: 这是一个关键的执行层,负责根据Midscene Core的指令,实际操作目标应用程序或UI。它能获取UI状态和截图,并将其反馈给Midscene Core。
目标应用程序/UI: 这是自动化操作的实际对象,可以是:
- 浏览器 (Browser):通过Playwright或Puppeteer等工具进行Web自动化。
- Android 应用 (Android App):进行Android自动化。
可视化报告 (Visual Reports): Midscene提供可视化报告,方便用户理解、回放和调试整个自动化过程。
Playground: 内置的Playground环境,允许用户通过自然语言指令进行调试。
缓存机制 (Caching Mechanism): Midscene利用缓存机制来提高效率,允许脚本更快地重放以获得结果。
主要的内置系统提示词
MidScene 的智能解析能力主要依托 LLM 大模型来实现,因此在调用 LLM 的时候,其设定的系统提示词就尤为关键。通过分析源码,可以看到 MidScene 针对不同类型的任务,设定了不同的系统提示词。总结如下:
1. 任务规划类 System Prompts
该项目包含三种不同的任务规划提示词:
传统LLM模型的任务规划提示词 - 用于指导传统语言模型将用户指令分解为一系列可执行的UI操作动作。
packages/core/src/ai-model/prompt/llm-planning.ts
| |
视觉-语言模型的任务规划提示词 - 专门针对具有视觉能力的AI模型(如Qwen-VL、Gemini)设计,能够直接处理截图并规划下一步动作。
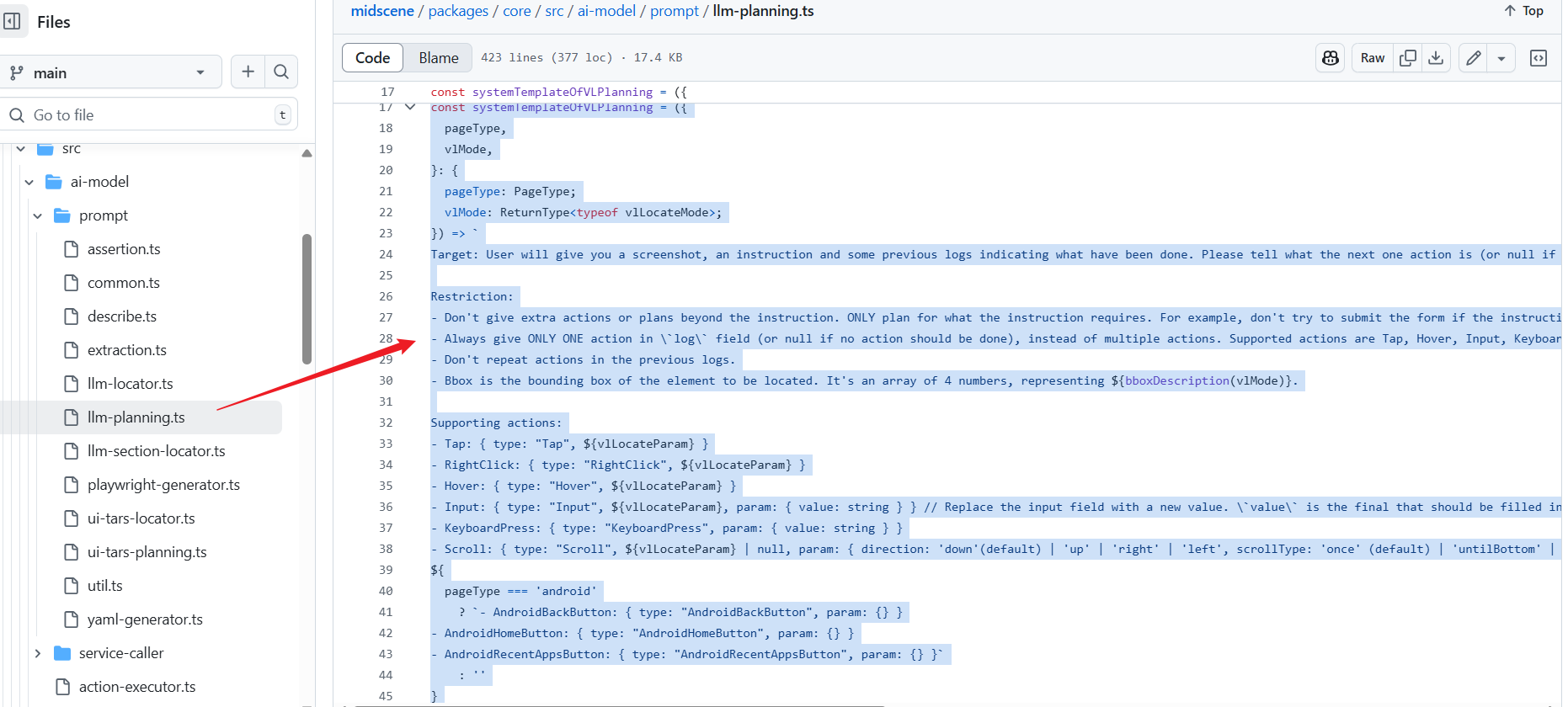
UI-Tars模型的任务规划提示词 - 为UI-Tars专门设计的GUI智能体提示词,采用思考-行动的格式。
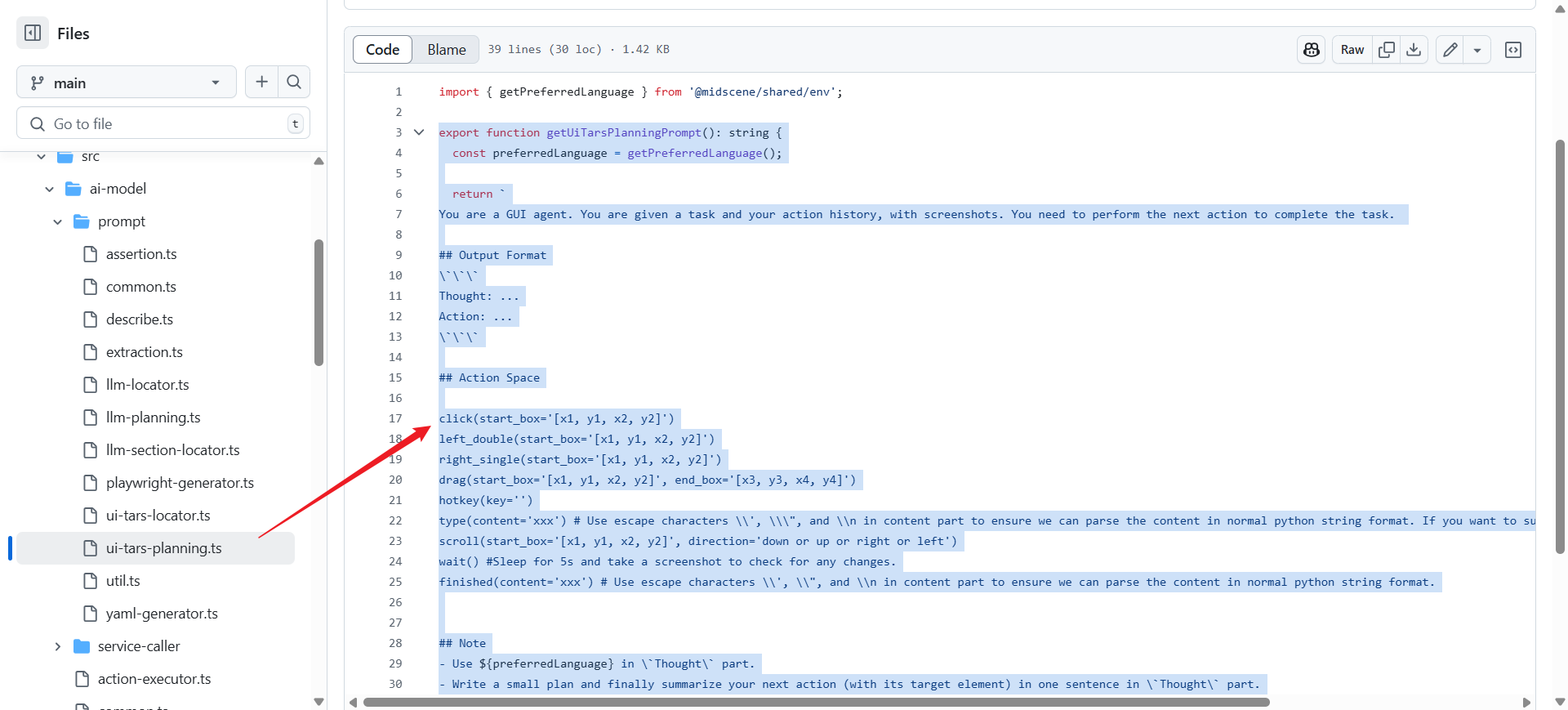
2. 元素定位类 System Prompts
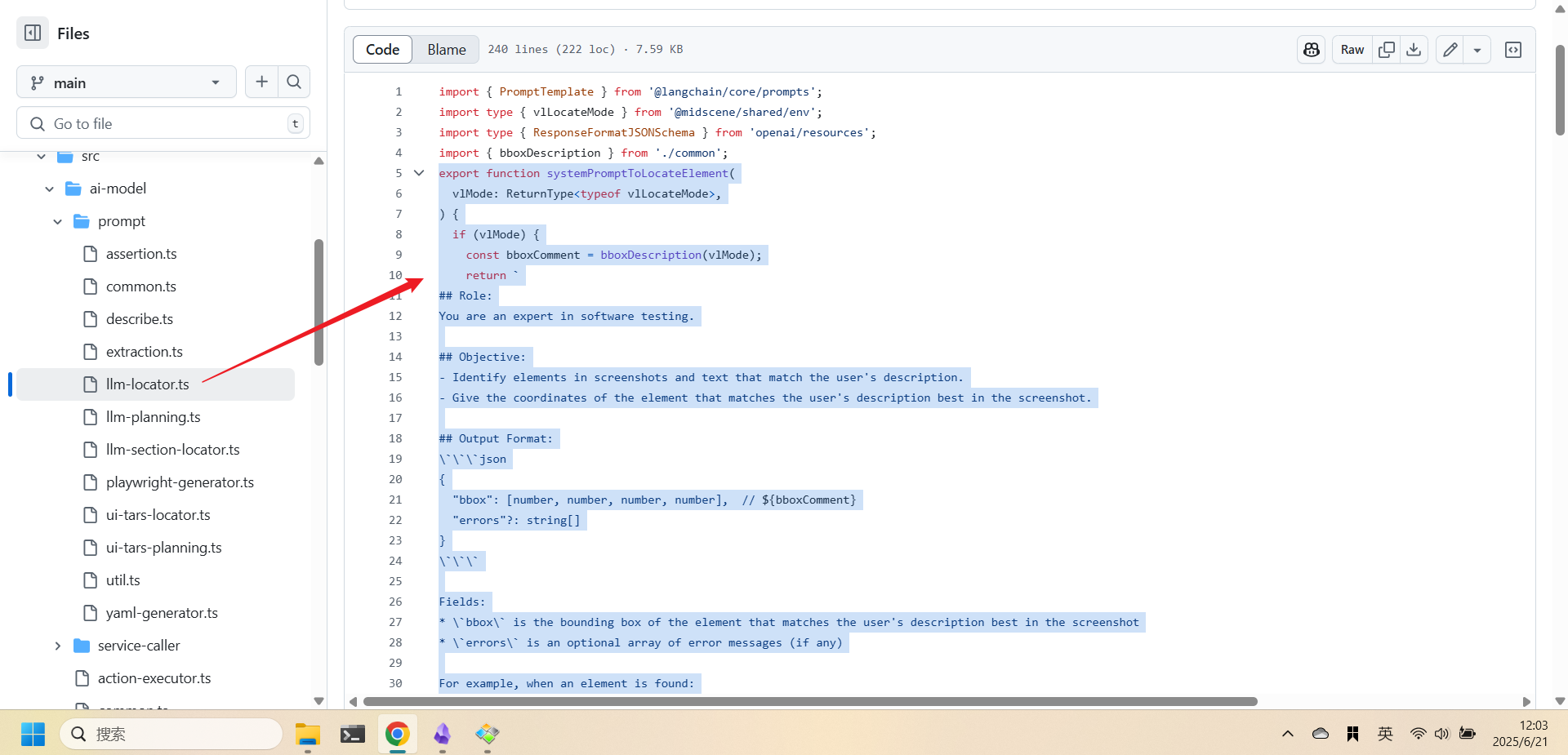
元素定位提示词 - 用于在页面截图和元素描述中精确定位目标元素,支持传统LLM和视觉-语言模型两种模式。
区域定位提示词 - 用于定位包含目标元素的页面区域,通常不超过300x300像素的区域。
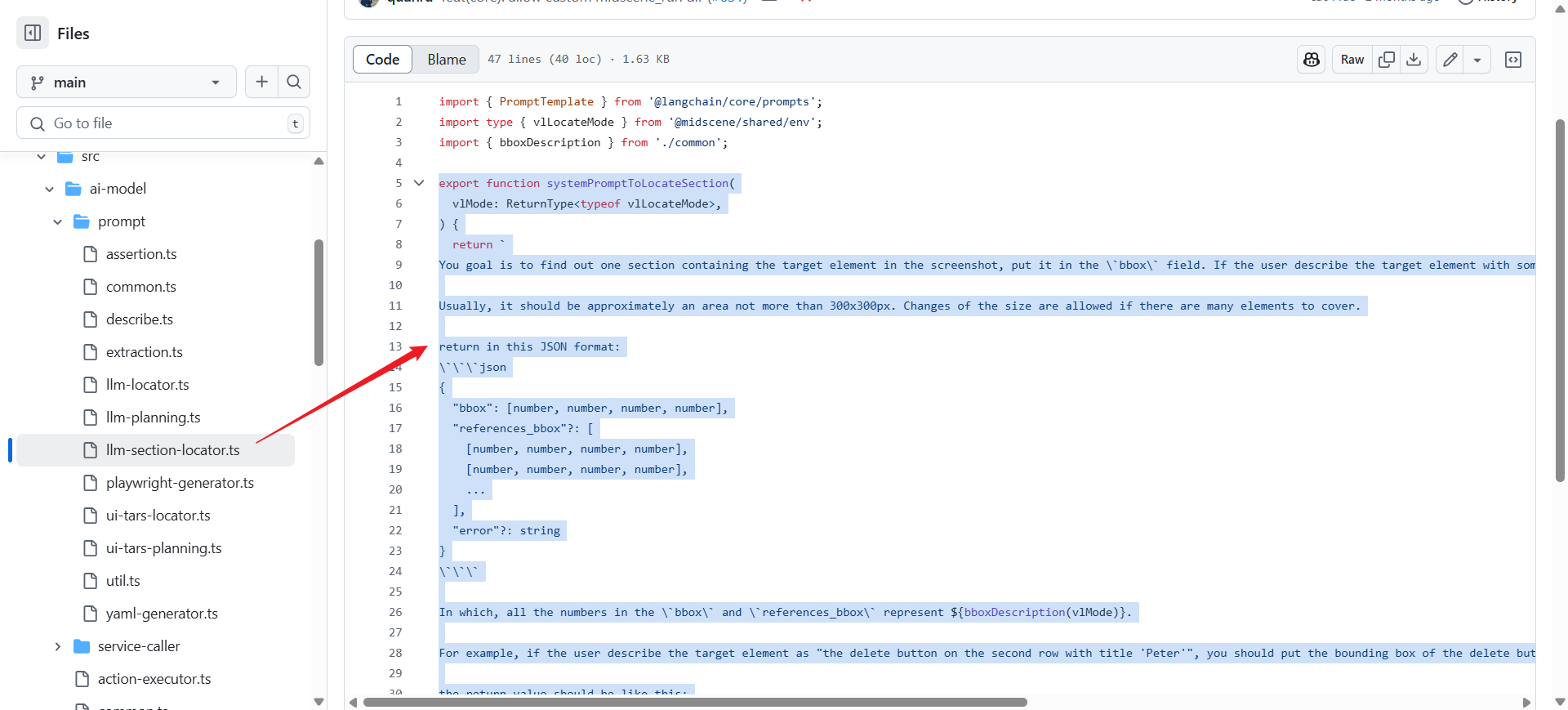
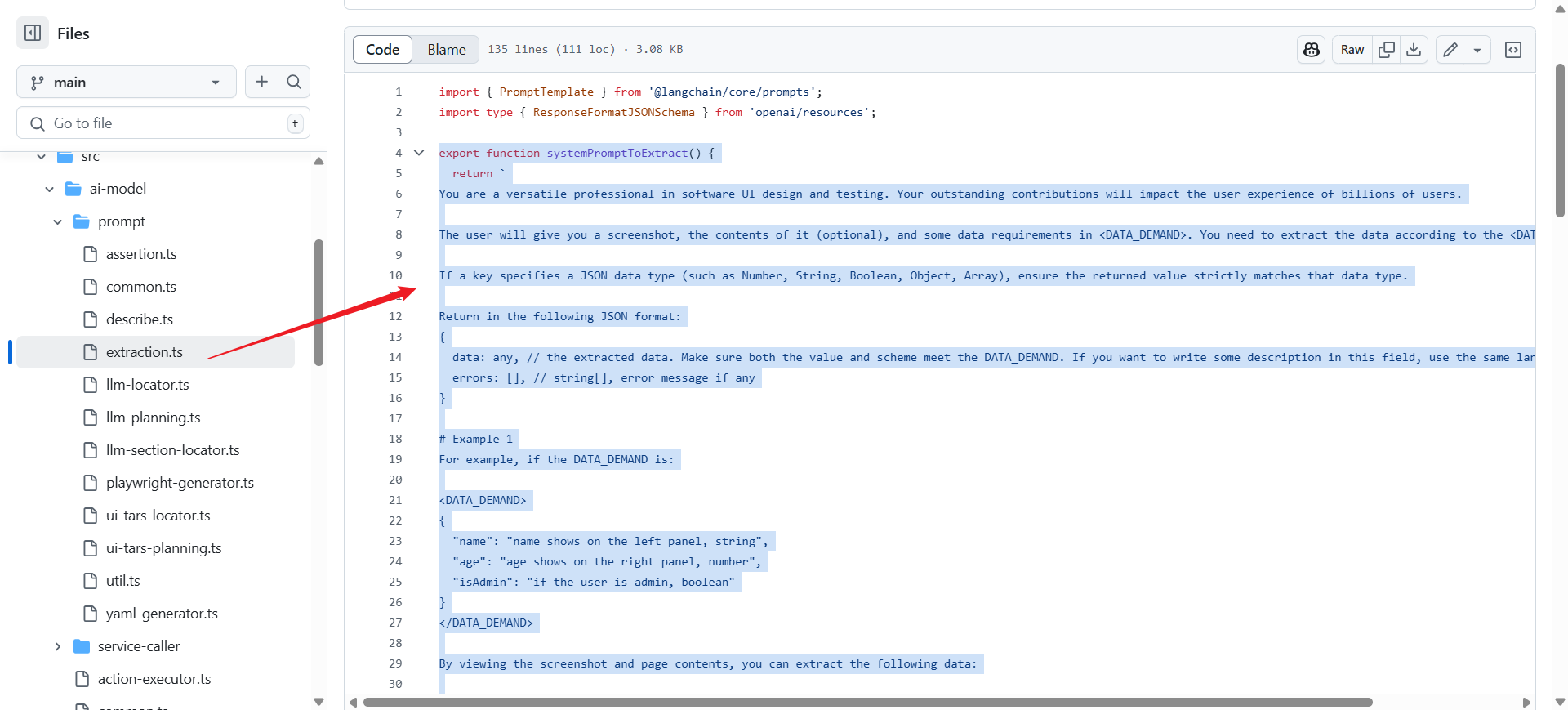
3. 数据提取类 System Prompts
数据提取提示词 - 指导AI从UI界面中提取结构化数据,支持多种数据类型和格式要求。
4. 断言验证类 System Prompts
断言验证提示词 - 用于验证页面状态是否符合预期的断言条件,支持UI-Tars和普通模型两种格式。
| |
5. 元素描述类 System Prompts
元素描述提示词 - 用于生成精确的元素描述,帮助识别页面中的特定UI元素(给定元素)。
| |
6. 代码生成类 System Prompts
Playwright测试代码生成提示词 - 基于录制的浏览器会话事件生成可执行的Playwright测试代码。
| |
通过对这些 system prompts 采用模块化设计,根据不同的AI模型类型(传统LLM vs 视觉-语言模型)和页面类型(web vs Android)来动态调整。项目还包含了完整的JSON schema定义来确保AI输出的结构化和一致性,并且支持多语言环境
${getPreferredLanguage()}
对用户提示词的补充和约束
除了通过这些系统提示词的设定,让LLM可以更好理解当前任务。对于用户的输入指令,即用户提示词,在实际处理时,必然还需要进行一定的扩展和约束补充。
这里我们再分析关于用户提示词的处理:
1. 背景上下文的智能生成
项目通过generateTaskBackgroundContext函数为用户指令添加结构化的背景上下文,包括高优先级知识和历史执行日志,防止重复执行相同的操作。
| |
2. 多模态适配的用户提示
根据AI模型的能力,用户提示会采用不同的格式。对于视觉语言模型,直接传递任务背景;对于传统LLM,则结合页面描述信息。
| |
3. 结构化JSON Schema验证
项目使用OpenAI的结构化输出schema来严格约束AI的响应格式,确保返回的数据符合预定义的结构,包括actions、log、error等必要字段。
| |
通过这些多层次的增强和约束机制,确保了AI模型能够准确理解用户意图,同时严格控制AI的行为边界。从提示词的定义来看,项目很注重防止AI产生幻觉或执行超出用户指令范围的操作,这对于UI自动化这种需要高精度操作的场景至关重要。
大模型上下文窗口限制
在利用各种AI大模型完成智能任务时,一个非常重要的约束,就是大模型通常是有着上下文窗口大小限制的,超过这个限制的历史信息会被丢弃,以节约大模型的资源,提升性能。
而对于一个自动化测试任务来说,分解拆分后的运行链路往往较长,通常都会超出LLM的上下文限制。
所以这里我们再分析一下这个项目对于上下文窗口限制的处理是如何实现的
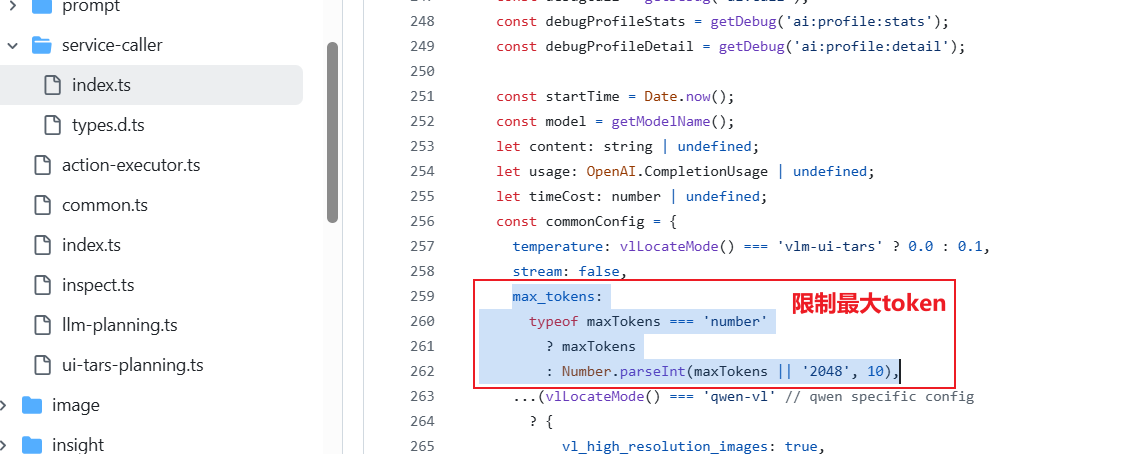
1. Token数量限制控制
项目通过OPENAI_MAX_TOKENS环境变量来设置响应的最大token数量
2. 图像尺寸限制和自动调整
项目针对不同模型实施图像尺寸限制,特别是对GPT-4o模型实施严格的尺寸控制。当检测到图像尺寸超过GPT-4o的最大输入限制(2000x768或768x2000像素)时,系统会发出警告 。
| |
3. 图像压缩和优化
系统通过图像压缩来减少数据传输量(packages/shared/src/img/transform.ts) ,包括:
- 设置图像质量为90%来平衡质量和文件大小
- 提供图像调整大小功能
- 支持base64格式的图像处理和转换
4. 选择合适的模型架构
项目支持两种不同类型的AI模型来优化token使用:
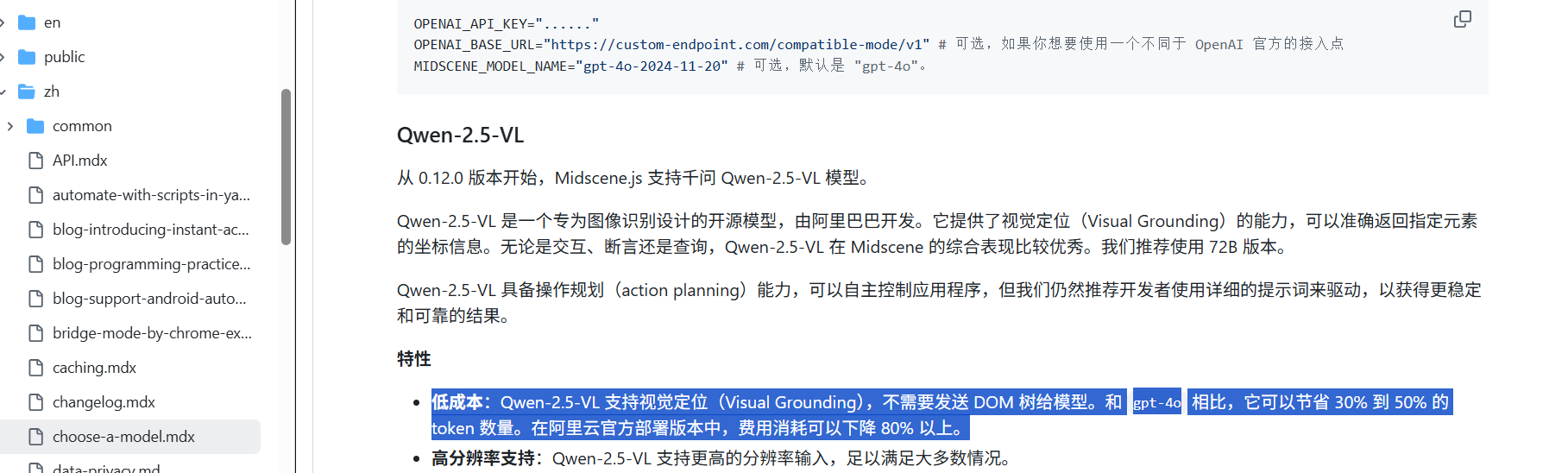
通用多模态LLM(如GPT-4o):需要同时发送截图和DOM树,导致token消耗较高 。
视觉定位VL模型(如Qwen-2.5-VL):支持视觉定位功能,不需要发送DOM树,可以节省30%到50%的token数量。
参见 apps/site/docs/zh/choose-a-model.mdx 文档中的说明
5. Token使用情况监控
项目还提供了详细的token使用情况跟踪和调试功能,记录prompt tokens、completion tokens和总token数量 。
总结来说,该项目的上下文窗口限制处理策略主要集中在三个方面:
- 控制输入数据量(通过图像压缩和尺寸限制)
- 选择合适的模型架构(VL模型vs通用LLM)
- 监控和优化token使用
这种多层次的处理方式有效地减少了对大型上下文窗口的需求,同时也保持了功能的完整性。
长链路任务的记忆管理
对于大模型来说,已完成步骤和历史任务的记忆对于保证结果的准确,避免无谓重复和节约成本意义重大,像我们之前文章介绍的如 Browser-Use这样的工具,会引入 mem0 这样的记忆框架来实现 AI 的记忆能力,那么Midscene在这方面是如何处理的呢?
基于对 Midscene 代码的分析,长链路任务的记忆管理主要通过以下几个核心机制实现:
任务缓存机制
Midscene 实现了一个智能的任务缓存系统来管理 AI 操作的记忆。该系统缓存规划结果和元素定位信息,避免重复的 AI 调用,从而减少内存消耗和提高执行效率。
packages/web-integration/src/common/task-cache.ts
缓存系统支持两种类型的缓存:
- 规划缓存 (PlanningCache) 用于存储 AI 规划的 YAML 工作流
- 定位缓存 (LocateCache) 用于存储元素的 XPath 信息。
对话历史管理
为了防止长链路任务中对话历史无限增长导致内存溢出,Midscene 实现了智能的对话历史管理策略。系统限制用户图像消息最多保留 4 条,采用先进先出 (FIFO) 策略自动清理旧的对话记录。
packages/web-integration/src/common/tasks.ts
重规划限制机制
为了防止 AI 在长链路任务中陷入无限重规划的死循环,系统设置了重规划次数限制。当重规划次数超过限制时,任务会主动终止并返回错误信息。
| |
资源清理机制
Midscene 使用 FreeFn 模式确保长链路任务完成后能够正确清理所有资源,包括网络连接、临时文件、定时器等。即使在异常情况下,资源清理机制也能保证系统资源得到释放。
packages/web-integration/src/yaml/player.ts
| |
上下文优化
为了减少内存占用,Midscene 还实现了多项上下文优化策略:
- 可见元素过滤:只提取页面中可见的元素,减少 DOM 树的大小
- 图像压缩:对截图进行智能压缩,减少内存和传输开销
- 视口裁剪:根据视口范围裁剪上下文数据
可以看到,虽然Mdscene没有引入专门的记忆框架来处理历史记忆,但还是建立了记忆管理机制来协同处理,使 Midscene 能够在处理复杂的长链路任务时保持高效的内存使用,通过对话历史管理控制记忆增长,重规划限制防止无限循环,通过资源清理确保系统稳定性,最终实现了一个可靠的长链路任务执行系统。
| |